[ECC DS 4주차] 1. A Complete Introduction Walkthrough
📢 컴퓨터 리소스 문제와 에러 해결을 하지 못해 실행 결과를 모두 지운 상태입니다. 각 셀의 실행 결과를 확인하려면 아래 링크를 참고해 주세요.
0. 대회 소개
-
📌 목적
- 개인과 가구 특성을 모두 사용하여 가구의 빈곤 수준을 예측할 수 있는 기계 학습 모델을 개발하는 것
-
📌 노트북 개요
-
문제 정의
-
데이터 세트에 대한 EDA
-
여러 기계 학습 모델 테스트/선택/최적화
-
모델의 출력 검사, 결론 도출
-
0-1. 데이터 설명
-
데이터는 train.csv와 test.csv 두 파일로 제공됨
-
train 세트: 9557개의 행(row) * 143개의 열(column)
-
test 세트: 23856개의 행(row) * 142개의 열(column)
-
-
각 행은
한 명의 개인 또는 한 가구를 나타내며, 각 열은 이들의 고유한특성을 나타냄
-
Target 구성(클래스 구성)
- 4가지 빈곤 수준
1 = 극심한 빈곤 가구 2 = 적당한 빈곤 가구 3 = 취약 가구 4 = 비취약가구 -
Columns
-
총 143개의 컬럼으로 구성됨
-
ID: 각 개인의 고유 식별자 -> 활용 x -
idhogar: 각 가구의 고유 식별자 -> 가구별로 개인을 그룹화하는 데 사용 -
parentesco1: 가장인지 여부(일종의 flag 변수)
-
0-2. 목표
-
가구 수준에서 빈곤 정도를 예측하는 것
- 개인 수준에 대한 데이터가 제공되며, 각 개인은 고유한 특징을 가지고 있을 뿐만 아니라 가구에 대한 정보도 가지고 있음
-
데이터 세트를 가공하기 위해 각 가정의 개별 데이터 집계가 요구됨
-
test set의 모든 개인에 대한 예측을 수행
-
“ONLY the heads of household are used in scoring”
-
가구 단위로 빈곤을 예측
-
⭐ 중요
-
한 가구의 모든 구성원이 train 데이터에서 동일한 레이블을 가져야 함
- 만약 다른 경우
parentesco1 == 1.0행으로 구분할 수 있는 각 가구의 가장에 대한 라벨을 사용
- 만약 다른 경우
-
모델 훈련 시 가장의 빈곤 수준이라는 라벨을 각 가구에 붙여서 가정 단위로 훈련시킬 예정
-
원본 데이터에는 가구 및 개인의 특성이 혼합되어 있음 ⇀ 개별 데이터의 경우 각 가구에 대해 이를 집계하는 방법을 찾아야 함
-
개인 중 일부는 가장이 없는 가구에 속함 ⇀ 훈련 데이터로 사용 불가
-
0-3. 평가 지표(metric) - Macro F1 Score
-
궁극적으로 우리는 가구의 빈곤 수준(정수로 구분됨)을 예측할 수 있는 기계 학습 모델을 구축하고자 함
-
평가 지표로
Macro F1 Score을 활용할 예정- 정밀도와 재현율의 조화 평균
-
표준 F1 점수
-
다중 분류 문제의 경우 각 클래스 별 F1 score을 평균내어 활용
-
Macro F1 score
-
label의 불균형을 고려하지 않고 각 클래스의 F1 점수를 평균
- 각 레이블의 발생 빈도는 매크로를 사용할 때 계산에 반영되지 않음(사용하려면
weighted옵션을 활용)
- 각 레이블의 발생 빈도는 매크로를 사용할 때 계산에 반영되지 않음(사용하려면
-
코드
from sklearn.metrics import f1_score f1_score(y_true, y_predicted, average = 'macro') -
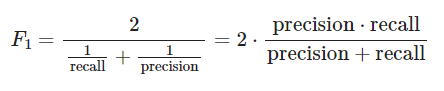
0-4. 로드맵(전반적인 진행 process)
-
문제 이해
-
탐색적 데이터 분석(EDA)
-
특성 공학(Feature Engineering)
-
Baseline ML 학습 모델 비교
-
좀 더 복잡한 기계 학습 모델 시도
-
선택한 모델 최적화
-
예측 수행 / 확인
-
결론 도출, 다음 단계 제시
1. 준비(Getting Started)
1-1. 라이브러리 import
### 데이터 변형(가공)
import pandas as pd
import numpy as np
### 시각화
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('fivethirtyeight')
plt.rcParams['font.size'] = 18
plt.rcParams['patch.edgecolor'] = 'k'
1-2. 데이터 준비하기
from google.colab import drive
drive.mount('/content/drive')
pd.options.display.max_columns = 150 # 최대 150 컬럼만 표시
train = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/ECC 48기 데과B/4주차/Costa Rica/data/train.csv')
test = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/ECC 48기 데과B/4주차/Costa Rica/data/test.csv')
train.head()
- 컬럼들 간의 순서는 존재하지 않는 것으로 판단된다.
2. EDA(Exploratory Data Analysis) & 전처리
2-1. 데이터 정보 확인
### 학습용 데이터
train.info()
-
130개의 integer형 컬럼, 8개의 float형 컬럼 및 5개의 object 컬럼이 존재
-
integer 컬럼의 경우 0 또는 1을 사용하는 bool 변수 또는 순서형(ordinal) 변수를 나타낼 수 있음
-
object 컬럼의 경우 기계 학습 모델에 직접 공급될 수 없음 -> 전처리 필요
### 테스트용 데이터
test.info()
a) 정수형(Integer) Columns
- 각 열에 대해 고유한 값의 수를 세고 그 결과를 막대 그래프로 표시
train.select_dtypes(np.int64).nunique().value_counts().sort_index().plot.bar(color = 'blue',
figsize = (8, 6),
edgecolor = 'k',
linewidth = 2)
plt.xlabel('Number of Unique Values')
plt.ylabel('Count')
plt.title('Count of Unique Values in Integer Columns')
-
고유한 값이 2개만 있는 컬럼은 boolean(0 또는 1)을 나타냄
-
대부분의 boolean 정보들은 대부분 가구 단위로 집계되어 있음
-
ex>
refrig컬럼- 가정에 냉장고가 있는지 없는지 0과 1로 표시
-
-
개인 수준으로 존재하는 컬럼들은 집겨 필요
b) Float Columns
-
float형 변수들의 경우 주로 연속형 변수를 나타냄
-
분포도 plot(dist plot)을 통해 float 변수들의 분포를 확인할 수 있음
- ‘OrderedDict’ 를 사용하여 빈곤 수준을 색상에 매핑
-
아래 그래프는
target값으로 표시된float열의 분포를 보여줌가구의 빈곤 수준에 따라 변수들의 분포에 유의한 차이가 있는지 확인할 수 있음
from collections import OrderedDict # 순서를 가지는 딕셔너리
### 시각화 format 설정
plt.figure(figsize = (20, 16))
plt.style.use('fivethirtyeight')
### Color 설정
colors = OrderedDict({1: 'red', 2: 'orange', 3: 'blue', 4: 'green'})
poverty_mapping = OrderedDict({1: 'extreme', 2: 'moderate',
3: 'vulnerable', 4: 'non vulnerable'})
### float형 변수들 각각에 대해...
for i, col in enumerate(train.select_dtypes('float')):
ax = plt.subplot(4, 2, i + 1) # plotting 위치 설정
# 각 가구별 빈곤 수준별로
for poverty_level, color in colors.items():
# 각각 다른 색상의 선으로 시각화
sns.kdeplot(train.loc[train['Target'] == poverty_level, col].dropna(),
ax = ax, color = color, label = poverty_mapping[poverty_level])
plt.title(f'{col.capitalize()} Distribution')
plt.xlabel(f'{col}')
plt.ylabel('Density')
plt.subplots_adjust(top = 2)
-
시각화를 통해 어떤 변수가 모형과 가장 관련이 있을지를 대략적으로 파악할 수 있음
-
ex>
-
meaneduc(가구 내 성인의 평균 교육을 나타냄)은 빈곤 수준과 관련이 있는 것으로 보임 -
meaneduc이 높을수록 빈곤 수준이 낮은 가구가 적음
-
-
c) Object Columns
train.select_dtypes('object').head()
-
id,idhogar: 변수 식별에 활용 -
dependency: 종속률, (19세 미만 또는 64세 이상 가구원 수)/(19세 이상 64세 미만 가구원 수) -
edjeefe: 남성 가장의 수년간 교육, 에스코라리(교육연수), 가장과 성별을 기반으로 yes = 1, no = 0로 표시 -
edjefa: 여성 가장의 수년간 교육, 에스코라리(교육연수), 가장과 성별을 기반으로 yes = 1 및 no = 0 -
세 변수에 대해 yes = 1, no = 0의 경우 매핑을 활용하여 변수를 수정하고 부동 소수점으로 변환
mapping = {"yes": 1, "no": 0}
### train, test에 대해 모두 같은 작업 수행
for df in [train, test]:
# mapping으로 데이터를 적절하게 변환
df['dependency'] = df['dependency'].replace(mapping).astype(np.float64)
df['edjefa'] = df['edjefa'].replace(mapping).astype(np.float64)
df['edjefe'] = df['edjefe'].replace(mapping).astype(np.float64)
train[['dependency', 'edjefa', 'edjefe']].describe()
- 제대로 변환되었음을 확인할 수 있다.
### 시각화
plt.figure(figsize = (16, 12))
### 각 변수들 별로..
for i, col in enumerate(['dependency', 'edjefa', 'edjefe']):
ax = plt.subplot(3, 1, i + 1)
# 각 가구별 빈곤 수준별로
for poverty_level, color in colors.items():
# 빈곤 수준별로 각각 다른 색으로 표시
sns.kdeplot(train.loc[train['Target'] == poverty_level, col].dropna(),
ax = ax, color = color, label = poverty_mapping[poverty_level])
plt.title(f'{col.capitalize()} Distribution')
plt.xlabel(f'{col}')
plt.ylabel('Density')
plt.subplots_adjust(top = 2)
-
해당 변수들이 숫자로 올바르게 표현됨
- ML 학습 모델에 입력될 수 있음
### test 데이터의 target 값을 일단 null로 초기화
test['Target'] = np.nan
data = train.append(test, ignore_index = True)
2-2. 라벨(target) 분포 확인
-
굉장히 불균형한(imbalanced) 분포를 가짐을 확인할 수 있음
-
정수(1~4)로 각 클래스가 구분되어 있음
-
라벨을 정확하게 확인하기 위해
parentesco1 == 1로 표시된(각 가정의 가장을 표시) 열만 고려
# 가장
heads = data.loc[data['parentesco1'] == 1].copy()
# 학습을 위한 라벨(target)
train_labels = data.loc[(data['Target'].notnull()) & (data['parentesco1'] == 1), ['Target', 'idhogar']]
# target 집계(분포 확인)
label_counts = train_labels['Target'].value_counts().sort_index()
# 각 label의 분포에 대한 막대 그래프
label_counts.plot.bar(figsize = (8, 6),
color = colors.values(),
edgecolor = 'k', linewidth = 2)
# 축, 제목 설정
plt.xlabel('Poverty Level'); plt.ylabel('Count');
plt.xticks([x - 1 for x in poverty_mapping.keys()],
list(poverty_mapping.values()), rotation = 60)
plt.title('Poverty Level Breakdown');
label_counts
-
target의 분포가 매우 불균형함
-
non_vernerable으로 분류되는 가구의 수가 다른 클래스에 비해 현저히 많음 -
extreme은 매우 적음
-
-
불균형 클래스 분류 문제의 경우 ML 모델이 훨씬 적은 예제를 보기 때문에 소수 클래스를 예측하는 데 어려움을 겪을 수 있음
-
이를 해결하기 위해 Oversampling을 적용할 수 있음
2-3. 잘못된 label 처리
-
일반적으로 데이터 과학 프로젝트에서 80%의 시간을 데이터를 정리하고 이상 징후/오류를 수정하는 데 할애
-
사람의 입력 오류, 측정 오류 또는 정확하지만 눈에 띄는 극단값 등
-
같은 가구임에도 개인은 빈곤 수준이 다른, 잘못된 라벨들이 존재함
- 가장의 라벨을 진정한(true) 라벨로 활용
-
잘못된 label을 찾아내기 위해 가구별로 데이터를 분류한 다음,
target의 고유값이 하나만 있는지 확인
# 가구별로 그룹화하고 고유값의 수 파악
all_equal = train.groupby('idhogar')['Target'].apply(lambda x: x.nunique() == 1)
# target 값이 모두 같지 않은 가구
not_equal = all_equal[all_equal != True]
print('가족 구성원이 모두 동일한 대상이 아닌 가구는 {}가구입니다.'.format(len(not_equal)))
- 예시를 확인해보자.
train[train['idhogar'] == not_equal.index[0]][['idhogar', 'parentesco1', 'Target']]
-
parentesco1 == 1로 확인 결과, 해당 가구의 경우 모든 구성원에 대한 올바른 레이블은 3(vulnerable)이다. -
해당 가구의 모든 구성원에서 올바른 빈곤 수준(target, label)을 재할당
cf> 가장이 없는 경우
households_leader = train.groupby('idhogar')['parentesco1'].sum()
# 가장이 없는 가구
households_no_head = train.loc[train['idhogar'].isin(households_leader[households_leader == 0].index), :]
print('There are {} households without a head.'.format(households_no_head['idhogar'].nunique()))
# 가장이 없는 가구들 중 구성원들 간의 레이블이 다른 가구 찾기
households_no_head_equal = households_no_head.groupby('idhogar')['Target'].apply(lambda x: x.nunique() == 1)
print('{} Households with no head have different labels.'.format(sum(households_no_head_equal == False)))
- 다행히 이러한 데이터는 존재하지 않는다.
잘못된 label 처리
### 라벨값이 같지 않은 각 가구별로..
for household in not_equal.index:
# 가장을 통해 제대로 된 label값 찾기
true_target = int(train[(train['idhogar'] == household) & (train['parentesco1'] == 1.0)]['Target'])
# 제대로 된 값으로 재할당
train.loc[train['idhogar'] == household, 'Target'] = true_target
# 가구별로 그룹화하고 고유값의 수 파악
all_equal = train.groupby('idhogar')['Target'].apply(lambda x: x.nunique() == 1)
# target 값이 통일되지 않은 가구
not_equal = all_equal[all_equal != True]
print('There are {} households where the family members do not all have the same target.'.format(len(not_equal)))
- 제대로 처리된 것을 확인할 수 있다.
2-4. 결측치(Missing Value) 처리
- 누락된 값은 ML 모델을 사용하기 전에 입력해야 하며, 변수에 따라 입력하는 최선의 전략을 생각해야 합
# 컬럼(변수)별로 결측치 개수 확인
missing = pd.DataFrame(data.isnull().sum()).rename(columns = {0: 'total'})
# 결측치의 비율 확인
missing['percent'] = missing['total'] / len(data)
missing.sort_values('percent', ascending = False).head(10).drop('Target')
-
결측값의 비율이 높은 세 개의 컬럼을 처리하자.
-
v18q1: 가족별로 소유한 태블릿 수-
가구 차원으로 보는 것이 타당함
-
가장에 대해서만 행을 선택
-
-
v2a1: 월세 -
rez_esc: 뒤떨어진 학년의 연 수
📌 Value Counts 시각화 함수
-
한 열의 카운트 값을 시각화
-
선택적으로 가장만 표시
def plot_value_counts(df, col, heads_only = False):
# 가장만 선택
if heads_only:
df = df.loc[df['parentesco1'] == 1].copy()
plt.figure(figsize = (8, 6))
df[col].value_counts().sort_index().plot.bar(color = 'blue',
edgecolor = 'k',
linewidth = 2)
plt.xlabel(f'{col}')
plt.ylabel('Count')
plt.title(f'{col} Value Counts')
plt.show()
a) v18q1
plot_value_counts(heads, 'v18q1')
-
일단은 가장 일반적으로 소유할 수 있는 태블릿의 수는 1인 것 같음
-
하지만, 결측 데이터에 대해서도 생각할 필요가 있음
-
해당 범주가
NaN인 가구는 태블릿을 소유하지 않을 수도 있음
-
-
v18q값을 기준으로 그룹화 한 다음v18q1에 대한 null 값의 수를 계산- null 값이 가족이 태블릿을 소유하지 않음을 나타내는 것인지를 확인 가능
heads.groupby('v18q')['v18q1'].apply(lambda x: x.isnull().sum())
-
v18q1에서 결측치를 가지는 가구의 경우 태블릿을 소유하지 않은 가구라는 점을 확인할 수 있음- 해당 값의 결측치를 0으로 채울 수 있음
### 결측치 처리
data['v18q1'] = data['v18q1'].fillna(0)
b) v2a1
-
월세 납부의 누락된 값을 살펴보는 것 외에도 주택의 소유/임대 상태를 보여주는 열에 있는
tipovivi의 분포를 살펴보는 것도 흥미로울 것임- 월세 지불에 대해 결측치가 있는 주택들의 소유 현황을 파악하자.
# 주택 소유를 나타내는 변수
own_variables = [x for x in data if x.startswith('tipo')]
# 주택 임대료 지급(결측치 O) vs 주택 소유(Plottinh)
data.loc[data['v2a1'].isnull(), own_variables].sum().plot.bar(figsize = (10, 8),
color = 'green',
edgecolor = 'k',
linewidth = 2)
plt.xticks([0, 1, 2, 3, 4],
['Owns and Paid Off', 'Owns and Paying', 'Rented', 'Precarious', 'Other'],
rotation = 60)
plt.title('Home Ownership Status for Households Missing Rent Payments', size = 18);
- 주택 소유 변수 설명:
tipovivi1 = 1: 전액을 지불한 본인 소유의 집
tipovivi2 = 1: 소유, 할부로 지불
tipovivi3 = 1: 임대 주택
tipovivi4 = 1: 불확실
tipovivi5 = 1: 기타(대여)
-
대부분 월세를 내지 않는 가구들은 일반적으로 자신의 집을 소유하고 있음
-
일부 상황에서는 결측치가 발생한 이유를 알 수 없음
-
소유하고 있고 월세가 누락된 주택의 경우 임대료 지급액을 0으로 설정할 수 있음
-
다른 주택의 경우 결측값을 냅둘 순 있지만 해당 가구에 결측값이 있음을 나타내는 플래그(부울) 열을 추가
# 집을 소유한 가구의 경우 월세 납부액 결측치를 0으로 표기
data.loc[(data['tipovivi1'] == 1), 'v2a1'] = 0
# 누락된 임대료 지급을 표기하는 컬럼 생성
data['v2a1-missing'] = data['v2a1'].isnull()
data['v2a1-missing'].value_counts()
c) rez_esc
-
결측치의 경우 가구에서 현재 학교에 다니는 자녀가 없을 수 있음
- 해당 열에 결측값이 있는 사람의 나이와 결측값이 없는 사람의 나이를 찾아 이를 확인하자.
### 결측치가 아닌 사람들의 나이
data.loc[data['rez_esc'].notnull()]['age'].describe()
-
결측치가 가장 많은 나이는 17세임
- 이것보다 나이가 많은 사람이라면, 우리는 단순히 이 사람들이 학교에 다니지 않는다고 가정할 수도 있음
### 데이터가 결측인 사람들의 나이
data.loc[data['rez_esc'].isnull()]['age'].describe()
-
대회 정보에 의하면 해당 변수는 7세에서 19세 사이의 개인에게만 정의됨
-
해당 범위보다 나이가 어린 사람이나 나이가 많은 사람은 값을 0으로 설정하면 됨
-
다른 사람의 경우 결측치를 처리하고, bool flag를 추가
-
# 19세 이상이거나 7세 미만인 사람 -> 0으로 결측치 처리
data.loc[((data['age'] > 19) | (data['age'] < 7)) & (data['rez_esc'].isnull()), 'rez_esc'] = 0
# 7세에서 19세 사이인 사람 중 결측치인 경우 flag 변수로 표시
data['rez_esc-missing'] = data['rez_esc'].isnull()
-
rez_esc에 이상치가 하나 존재함-
대회 설명에 의하면, 해당 변수의 최댓값은 5
-
5보다 큰 값들을 5로 재할당
-
### 이상치 처리
data.loc[data['rez_esc'] > 5, 'rez_esc'] = 5
2-5. 범주형 변수 시각화
-
두 범주형 변수가 서로 상호작용하는 방식을 보여주기 위해 산점도,누적막대그림, 상자그림 등 여러 가지 표시 옵션이 있음
-
각각의 x 값에 대한 y값의 백분율을 점의 크기로 표현하는 산점도 그림으로 시각화 진행
### 산점도 시각화를 위한 함수 정의
def plot_categoricals(x, y, data, annotate = True):
"""
- 두 범주형의 카운트를 표시합니다.
- size: 각 그룹의 카운트 수
- percentage: y의 주어진 값에 대한 것
"""
# Raw counts
raw_counts = pd.DataFrame(data.groupby(y)[x].value_counts(normalize = False))
raw_counts = raw_counts.rename(columns = {x: 'raw_count'})
# x 및 y의 각 그룹에 대한 카운트 계산
counts = pd.DataFrame(data.groupby(y)[x].value_counts(normalize = True)) # 정규화 수행
# 열 이름 변경 및 인덱스 재설정
counts = counts.rename(columns = {x: 'normalized_count'}).reset_index()
counts['percent'] = 100 * counts['normalized_count']
# Add the raw count
counts['raw_count'] = list(raw_counts['raw_count'])
# 백분율로 크기가 조정된 산점도
plt.figure(figsize = (14, 10))
plt.scatter(counts[x], counts[y], edgecolor = 'k', color = 'lightgreen',
s = 100 * np.sqrt(counts['raw_count']), marker = 'o',
alpha = 0.6, linewidth = 1.5)
if annotate:
# 텍스트로 플롯에 주석 달기
for i, row in counts.iterrows():
plt.annotate(xy = (row[x] - (1 / counts[x].nunique()),
row[y] - (0.15 / counts[y].nunique())),
color = 'navy',
text = f"{round(row['percent'], 1)}%")
# 축 설정
plt.yticks(counts[y].unique())
plt.xticks(counts[x].unique())
# 제곱근 영역에서 최소 및 최대를 균등한 공간으로 변환
sqr_min = int(np.sqrt(raw_counts['raw_count'].min()))
sqr_max = int(np.sqrt(raw_counts['raw_count'].max()))
# 5 sizes for legend
msizes = list(range(sqr_min, sqr_max,
int(( sqr_max - sqr_min) / 5)))
markers = []
# Markers for legend
for size in msizes:
markers.append(plt.scatter([], [], s = 100 * size,
label = f'{int(round(np.square(size) / 100) * 100)}',
color = 'lightgreen',
alpha = 0.6, edgecolor = 'k', linewidth = 1.5))
# Legend and formatting
plt.legend(handles = markers, title = 'Counts',
labelspacing = 3, handletextpad = 2,
fontsize = 16,
loc = (1.10, 0.19))
plt.annotate(f'* Size represents raw count while % is for a given y value.',
xy = (0, 1), xycoords = 'figure points', size = 10)
# Adjust axes limits
plt.xlim((counts[x].min() - (6 / counts[x].nunique()),
counts[x].max() + (6 / counts[x].nunique())))
plt.ylim((counts[y].min() - (4 / counts[y].nunique()),
counts[y].max() + (4 / counts[y].nunique())))
plt.grid(None)
plt.xlabel(f"{x}"); plt.ylabel(f"{y}"); plt.title(f"{y} vs {x}");
plot_categoricals('rez_esc', 'Target', data)
-
마커의 크기: raw count
-
해석
= 지정된 y 값을 선택한 다음 행 전체를 읽기
- 예시: 빈곤 수준이 1인 경우, 93%의 개인이 1년 이상 뒤처지지 않고 총 800명 정도의 개인이 있으며, 약 0.4%의 개인이 5년 뒤쳐져 있으며, 이 범주에 속하는 총 50명 정도의 개인이 있음
-
해당 그림은 전체 카운트와 범주 내 비율을 모두 표시
plot_categoricals('escolari', 'Target', data, annotate = False)
-
결측치 중 남은 값은 중간값으로 채우자.
-
target 값 분포를 시각화하여 결측값을 확인할 수 있음
plot_value_counts(data[(data['rez_esc-missing'] == 1)], 'Target')
- 해당 분포는 전체 데이터에 대한 분포와 일치하는 것으로 보임
plot_value_counts(data[(data['v2a1-missing'] == 1)], 'Target')
-
target = 2(moderate)의 비율이 높음
- 더 많은 빈곤의 지표가 될 수 있음
3. 특성 공학(Feature Engineering)
-
학습을 위해서는 각 가구에 대해 요약된 모든 정보가 필요함
- 가구 내의 개인을
groupby()하고 개별 변수의agg()를 수행하는 것을 의미
- 가구 내의 개인을
-
이후 특성 공학을 자동화시키는 방법도 있음
3-1. 컬럼(변수) 정의하기
-
data descriptions 를 통해 개인 수준과 가구 수준에 있는 열을 정의해야 함
- 변수 자체를 검토
-
일부 변수는 다른 방식으로 처리해야 하기 때문에 다른 변수를 정의
- 각 수준에서 정의된 변수를 사용하면 필요에 따라 변수를 집계할 수 있음
-
진행 프로세스
-
변수를 가구 수준과 개인 수준으로 나누기
-
개인 수준의 데이터에 적합한 집계 찾기
-
순서형(ordinal) 변수: 통계적 집계 활용
-
논리형(bool)변수: 집계할 수는 있지만, 통계치의 종류는 적음
- 개인 수준의 집계를 가구 수준 데이터에 결합
📌 변수들의 범주 정의하기
- 변수에는 여러 가지 범주가 있음
- Individual Variables: 개인별 특성
-
boolean: yes or no(0 또는 1)
-
ordered discrete: 순서가 있는 정수
- Household variables
-
boolean: Yes or No
-
ordered discrete: 순서가 있는 정수
-
연속형 수치
-
Squared Variables: 데이터의 (변수)^2에서 파생
-
Id variables: 데이터를 식별용, 피쳐로 사용 x
### Id variables
id_ = ['Id', 'idhogar', 'Target']
### Individual Variables
ind_bool = ['v18q', 'dis', 'male', 'female', 'estadocivil1', 'estadocivil2', 'estadocivil3',
'estadocivil4', 'estadocivil5', 'estadocivil6', 'estadocivil7',
'parentesco1', 'parentesco2', 'parentesco3', 'parentesco4', 'parentesco5',
'parentesco6', 'parentesco7', 'parentesco8', 'parentesco9', 'parentesco10',
'parentesco11', 'parentesco12', 'instlevel1', 'instlevel2', 'instlevel3',
'instlevel4', 'instlevel5', 'instlevel6', 'instlevel7', 'instlevel8',
'instlevel9', 'mobilephone', 'rez_esc-missing']
ind_ordered = ['rez_esc', 'escolari', 'age']
### Household variables
hh_bool = ['hacdor', 'hacapo', 'v14a', 'refrig', 'paredblolad', 'paredzocalo',
'paredpreb','pisocemento', 'pareddes', 'paredmad',
'paredzinc', 'paredfibras', 'paredother', 'pisomoscer', 'pisoother',
'pisonatur', 'pisonotiene', 'pisomadera',
'techozinc', 'techoentrepiso', 'techocane', 'techootro', 'cielorazo',
'abastaguadentro', 'abastaguafuera', 'abastaguano',
'public', 'planpri', 'noelec', 'coopele', 'sanitario1',
'sanitario2', 'sanitario3', 'sanitario5', 'sanitario6',
'energcocinar1', 'energcocinar2', 'energcocinar3', 'energcocinar4',
'elimbasu1', 'elimbasu2', 'elimbasu3', 'elimbasu4',
'elimbasu5', 'elimbasu6', 'epared1', 'epared2', 'epared3',
'etecho1', 'etecho2', 'etecho3', 'eviv1', 'eviv2', 'eviv3',
'tipovivi1', 'tipovivi2', 'tipovivi3', 'tipovivi4', 'tipovivi5',
'computer', 'television', 'lugar1', 'lugar2', 'lugar3',
'lugar4', 'lugar5', 'lugar6', 'area1', 'area2', 'v2a1-missing']
hh_ordered = [ 'rooms', 'r4h1', 'r4h2', 'r4h3', 'r4m1','r4m2','r4m3', 'r4t1', 'r4t2',
'r4t3', 'v18q1', 'tamhog','tamviv','hhsize','hogar_nin',
'hogar_adul','hogar_mayor','hogar_total', 'bedrooms', 'qmobilephone']
hh_cont = ['v2a1', 'dependency', 'edjefe', 'edjefa', 'meaneduc', 'overcrowding']
sqr_ = ['SQBescolari', 'SQBage', 'SQBhogar_total', 'SQBedjefe',
'SQBhogar_nin', 'SQBovercrowding', 'SQBdependency', 'SQBmeaned', 'agesq']
- 중복 여부/ 빠진 변수 확인
x = ind_bool + ind_ordered + id_ + hh_bool + hh_ordered + hh_cont + sqr_
from collections import Counter
print('There are no repeats: ', np.all(np.array(list(Counter(x).values())) == 1))
print('We covered every variable: ', len(x) == data.shape[1]) # 열의 개수와 동일한지 확인
⏺ Squared Variables
-
선형 모형이 비선형 관계를 학습하는 데 도움이 될 수 있기 때문에, 변수가 피쳐 엔지니어링의 일부로 제곱되거나 변환되는 경우가 존재
-
더 복잡한 모델을 사용할 것이기 때문에 이러한 squared feature들이 중복됨
-
제곱되지 않은 feature들과 높은 상관관계 -> 관련 없는 정보를 추가하고 학습을 느리게 함으로써 모델 성능에 영향을 미칠 수 있음
-
ex>
SQBagevsage
sns.lmplot(x = 'age', y = 'SQBage', data = data, fit_reg = False);
plt.title('Squared Age versus Age');
-
두 변수의 상관계수가 매우 크다.
- 데이터에 두 변수 모두들 저장할 필요가 x
# 제곱한 변수 제거하기
data = data.drop(columns = sqr_)
data.shape
⏺ Id Variables
- 데이터 식별에 필요 -> 유지
⏺ Household Variables
heads = data.loc[data['parentesco1'] == 1, :]
heads = heads[id_ + hh_bool + hh_cont + hh_ordered]
heads.shape
-
대부분의 가구 수준 변수의 경우 그대로 유지할 수도 있음
-
일부 중복 변수를 제거하고 기존 데이터에서 파생된 기능을 추가할 수도 있음
중복된 Household Variables
- 상관 관계가 너무 높은 변수가 있으면 상관 관계가 높은 변수 쌍 중 하나를 제거할 수 있음
# 상관계수 행렬
corr_matrix = heads.corr()
# 상삼각행렬만 남기기
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(np.bool))
# 상관 관계가 0.95보다 큰 feeature column의 인덱스 찾기
to_drop = [column for column in upper.columns if any(abs(upper[column]) > 0.95)]
to_drop
corr_matrix.loc[corr_matrix['tamhog'].abs() > 0.9, corr_matrix['tamhog'].abs() > 0.9]
sns.heatmap(corr_matrix.loc[corr_matrix['tamhog'].abs() > 0.9, corr_matrix['tamhog'].abs() > 0.9],
annot=True, cmap = plt.cm.autumn_r, fmt='.3f');
-
집의 크기와 관련된 몇 가지 변수가 있음
-
r4t3: 가구 내 총 인원수 -
tamhog: 가구 크기 -
tamviv: 가구에 사는 사람들의 수 -
hhsize: 가구 크기 -
hogar_total: 가구 구성원 수
-
-
이 변수들은 모두 서로 높은 상관 관계를 가짐
-
hhsize는tamhog와hogar_total과 완벽한 양의 상관관계를 가짐 -
rt4t3과hhsize는 거의 완벽한 상관관계를 가짐
두 변수 중 하나를 제거할 수 있음
-
heads = heads.drop(columns = ['tamhog', 'hogar_total', 'r4t3'])
- hhsize vs tamviv
sns.lmplot(x = 'tamviv', y = 'hhsize', data = data, fit_reg = False);
plt.title('Household size vs number of persons living in the household');
- 가족보다 가구에 더 많은 사람들이 살고 있음..?
~(무슨 의미인지..)~
heads['hhsize-diff'] = heads['tamviv'] - heads['hhsize']
plot_categoricals('hhsize-diff', 'Target', heads)
- 대부분의 가구는 차이가 없지만 가구 구성원보다 가구에 살고 있는 사람의 수가 많은 경우가 적지만 존재함
- coopele 변수
corr_matrix.loc[corr_matrix['coopele'].abs() > 0.9, corr_matrix['coopele'].abs() > 0.9]
-
coopele: 가정의 전기가 어디에서 오는지를 나타냄 -
네 가지 선택지가 있는데, 이 두 가지 선택지 중 하나가 없는 가정은 전기가 없거나(
noelec) 개인 발전소에서 공급받음(planpri)
0: No electricity
1: Electricity from cooperative
2: Electricity from CNFL, ICA, ESPH/JASEC
3: Electricity from private plant
-
정렬된 변수에는 고유한 순서가 있으며, 도메인 지식에 기반하여 선택
-
새로운 순서형 변수를 생성한 다음, 기존의 변수들을 삭제해도 ok
-
결측치인 데이터의 경우
NaN을 입력하고 boolean 컬럼으로 해당 변수에 대한 정보가 없음을 표시
elec = []
# 값 할당(mapping)
for i, row in heads.iterrows():
if row['noelec'] == 1:
elec.append(0)
elif row['coopele'] == 1:
elec.append(1)
elif row['public'] == 1:
elec.append(2)
elif row['planpri'] == 1:
elec.append(3)
else:
elec.append(np.nan)
# 결측치 처리
heads['elec'] = elec
heads['elec-missing'] = heads['elec'].isnull()
# 기존 컬럼 제거
# heads = heads.drop(columns = ['noelec', 'coopele', 'public', 'planpri'])
plot_categoricals('elec', 'Target', heads)
- target의 모든 값에 대해 가장 일반적인 전기 공급원이 나열된 공급업체 중 하나임을 알 수 있음
-
area2 변수
-
집이 시골 지역에 있다는 것을 의미
- 집이 도시 지역에 있는지를 나타내는 열(area1)이 있기 때문에 중복됩
해당 열 삭제
heads = heads.drop(columns = 'area2')
heads.groupby('area1')['Target'].value_counts(normalize = True)
- 도시 지역의 가구(value = 1)는 농촌 지역의 가구(value = 0)보다 빈곤 수준이 낮을 가능성이 더 높은 것으로 판단됨
⏺ Ordinal Variables
-
집의 벽, 지붕, 바닥에는 각각 3개의 column이 존재함
- ‘bad’, ‘regular’, ‘good’
-
변수를 boolean 형으로 냅둘 수도 있지만, bad < regular < good이라는 명확한 순서가 존재함
-
순서형 변수로 바꾸는 것이 더 좋아 보임
-
np.argmax()를 통해 각 가구에 대해 0이 아닌 열을 쉽게 찾을 수 있음
-
### Wall ordinal variable
heads['walls'] = np.argmax(np.array(heads[['epared1', 'epared2', 'epared3']]),
axis = 1)
# heads = heads.drop(columns = ['epared1', 'epared2', 'epared3'])
plot_categoricals('walls', 'Target', heads)
### Roof ordinal variable
heads['roof'] = np.argmax(np.array(heads[['etecho1', 'etecho2', 'etecho3']]),
axis = 1)
heads = heads.drop(columns = ['etecho1', 'etecho2', 'etecho3'])
### Floor ordinal variable
heads['floor'] = np.argmax(np.array(heads[['eviv1', 'eviv2', 'eviv3']]),
axis = 1)
# heads = heads.drop(columns = ['eviv1', 'eviv2', 'eviv3'])
3-2. 변수(feature) 구성하기
-
변수를 순서형 피처에 매핑하는 것 외에도 기존 데이터에서 완전히 새로운 피처를 생성할 수도 있음
- 예시> 이전의 세 가지 특징(wall, roof, floor)을 합산하여 집 구조의 전반적인 품질을 측정할 수 있음
-
walls + roof + floor
# 새로운 feature 생성하기
heads['walls+roof+floor'] = heads['walls'] + heads['roof'] + heads['floor']
plot_categoricals('walls+roof+floor', 'Target', heads, annotate = False)
- 새로운 feature는 target = 4(the lowest poverty level)에서
house quality변수의 값이 더 높은 경향이 있는 것처럼 보임
counts = pd.DataFrame(heads.groupby(['walls+roof+floor'])['Target'].value_counts(normalize = True)).rename(columns = {'Target': 'Normalized Count'}).reset_index()
counts.head()
-
warning
-
집의 질에 대한 경고
-
화장실, 전기, 바닥, 수도, 천장이 없는 경우 각각 -1점의 마이너스 값
# No toilet, no electricity, no floor, no water service, no ceiling
heads['warning'] = 1 * (heads['sanitario1'] +
(heads['elec'] == 0) +
heads['pisonotiene'] +
heads['abastaguano'] +
(heads['cielorazo'] == 0))
### seaborn의 violin plot으로 시각화
plt.figure(figsize = (10, 6))
sns.violinplot(x = 'warning', y = 'Target', data = heads)
plt.title('Target vs Warning Variable');
-
바이올린 플롯은 대상이 실제보다 더 작고 더 큰 값을 가질 수 있는 것처럼 보이는 효과로 범주형 변수를 평활(smoothing)하기 때문에 여기서는 적합하지 않은 것으로 판단됨
- 하지만, 경고 신호가 없는 가구 그룹에 빈곤 수준이 가장 낮은 가구들이 집중된 것을 확인할 수 있음
plot_categoricals('warning', 'Target', data = heads)
-
bonus
-
냉장고, 컴퓨터, 태블릿, 텔레비전을 가지고 있으면 점수가 올라가는 변수
# Owns a refrigerator, computer, tablet, and television
heads['bonus'] = 1 * (heads['refrig'] +
heads['computer'] +
(heads['v18q1'] > 0) +
heads['television'])
sns.violinplot(x = 'bonus', y = 'Target',
data = heads, figsize = (10, 6))
plt.title('Target vs Bonus Variable');
3-3. Per Capita Features
-
가구원 별로 특정 측정값의 수를 계산
-
특정값 / 가구 구성원 수
heads['phones-per-capita'] = heads['qmobilephone'] / heads['tamviv']
heads['tablets-per-capita'] = heads['v18q1'] / heads['tamviv']
heads['rooms-per-capita'] = heads['rooms'] / heads['tamviv']
heads['rent-per-capita'] = heads['v2a1'] / heads['tamviv']
3-4. Household Variables 살펴보기
- 관계를 정량화
a) 상관관계 확인하기
- 두 변수 사이의 관계를 측정하는 데는 여러 가지 방법이 있음
1. Pearson Correlation
-
-1부터 1까지 두 변수 사이의 선형 관계 측정
-
증가 추세가 정확하게 선형인 경우에만 하나가 될 수 있음
2. Spearman Correlation
-
-1에서 1까지 두 변수의 단조로운 관계를 측정
-
한 변수가 증가함에 따라 관계가 선형적이지 않더라도 다른 변수도 증가하는 경우 상관계수가 1임
-
스피어만 상관계수 계산에는 관계의 중요성 수준을 나타내는
p-value도 함께 산출됨p-value가 0.05 미만이면 일반적으로 유의한 것으로 간주됨
- 상관계수 해석
- 0.00 ~ 0.19: "매우 약한 상관관계"
- 0.20 ~ 0.39: "약한 상관관계"
- 0.40 ~ 0.59: "어느 정도의 상관관계"
- 0.60 ~ 0.79: "강한 상관관계"
- 0.80 ~ 1.0: "매우 강한 상관관계"
-
대부분의 경우 두 상관관계는 비슷함
-
스피어만 상관관계는 종종 순서형 변수에 대해 더 나은 방법이라고 판단됨
-
실제 세계에서 대부분의 관계는 선형적이지 않음
-
Pearson 상관관계는 두 변수가 얼마나 관련되어 있는지에 대한 근사치일 순 있지만, 정확하지 않고 가장 좋은 비교 방법 또한 아님
-
from scipy.stats import spearmanr
### 상관계수 시각화
def plot_corrs(x, y):
# 상관계수 계산
spr = spearmanr(x, y).correlation
pcr = np.corrcoef(x, y)[0, 1]
# 산점도 plot
data = pd.DataFrame({'x': x, 'y': y})
plt.figure( figsize = (6, 4))
sns.regplot(data = data, x = 'x', y = 'y', fit_reg = False)
plt.title(f'Spearman: {round(spr, 2)}; Pearson: {round(pcr, 2)}')
- Example
x = np.array(range(100))
y = x ** 2
plot_corrs(x, y)
x = np.array([1, 1, 1, 2, 3, 3, 4, 4, 4, 5, 5, 6, 7, 8, 8, 9, 9, 9])
y = np.array([1, 2, 1, 1, 1, 1, 2, 2, 2, 2, 1, 3, 3, 2, 4, 2, 2, 4])
plot_corrs(x, y)
x = np.array(range(-19, 20))
y = 2 * np.sin(x)
plot_corrs(x, y)
📌 Pearson 상관 관계
### 학습(train) 데이터만 사용
train_heads = heads.loc[heads['Target'].notnull(), :].copy()
pcorrs = pd.DataFrame(train_heads.corr()['Target'].sort_values()).rename(columns = {'Target': 'pcorr'}).reset_index()
pcorrs = pcorrs.rename(columns = {'index': 'feature'})
print('Most negatively correlated variables:')
print(pcorrs.head())
print('\nMost positively correlated variables:')
print(pcorrs.dropna().tail())
-
음의 상관관계의 경우 변수의 값이 증가할수록 target값이 감소함을 의미
- 빈곤 심각도가 증가함을 의미
-
warning이 증가함에 따라 빈곤 수준도 증가- 이는 집에 대한 잠재적인 나쁜 징후를 보여주기 위한 것이기 때문에 타당함
-
hogar_nin-
이는 가족 내 0~19명의 아이들의 숫자로, 더 어린 아이들이 더 높은 수준의 빈곤으로 이어지는 가족에게 스트레스의 재정적인 원인이 될 수 있다는 것을 의미
-
사회 경제적 지위가 낮은 가정들은 그들 중 한 명이 성공할 수 있기를 바라는 마음으로 더 많은 아이들을 가지는 경향이 있음
가족 규모와 빈곤 사이에는 실질적인 연관성이 있다.
-
-
양의 상관관계의 경우, 변수의 값이 증가할수록 Target값이 증가함을 의미
- 빈곤 심각도가 감소함을 의미
-
meaneduc-
가구 내 성인의 평균 교육 수준을 나타내는 가구 수준의 변수
-
target과 가장 높은 양의 상관관계를 보임
교육의 낮은 수준은 일반적으로 빈곤의 낮은 수준과 상관관계가 있다.
-
-
변수와 target 간에 약한 상관관계가 존재함을 확인할 수 있음
📌 스피어만 상관 관계
import warnings
warnings.filterwarnings('ignore', category = RuntimeWarning)
feats = [] # features
scorr = [] # scores
pvalues = [] # p-value
# 각 컬럼(변수)별로
for c in heads:
# 숫자형 변수들에 대해..
if heads[c].dtype != 'object':
feats.append(c)
# 스피어만 상관계수 계산
scorr.append(spearmanr(train_heads[c], train_heads['Target']).correlation)
pvalues.append(spearmanr(train_heads[c], train_heads['Target']).pvalue)
scorrs = pd.DataFrame({'feature': feats, 'scorr': scorr, 'pvalue': pvalues}).sort_values('scorr')
-
p-value가 0.05 미만이면 일반적으로 유의한 것으로 간주됨
- 우리는 다중 비교를 수행하기 때문에 p-value를 비교 횟수로 나누고자 함
Bonferroni 수정이라 함
print('Most negative Spearman correlations:')
print(scorrs.head())
print()
print('\nMost positive Spearman correlations:')
print(scorrs.dropna().tail())
- 상관관계를 측정하는 두 계수 모두 비슷한 결과를 보이고 있다.
corrs = pcorrs.merge(scorrs, on = 'feature')
corrs['diff'] = corrs['pcorr'] - corrs['scorr'] # p-value - 상관계수
corrs.sort_values('diff').head()
corrs.sort_values('diff').dropna().tail()
dependency변수가 가장 큰 차이를 보임
### 시각화
# 두 변수 모두 이산형 변수이기에, plot에 약간의 jitter를 추가함
sns.lmplot(x = 'dependency', y = 'Target', fit_reg = True, data = train_heads,
x_jitter = 0.05, y_jitter = 0.05)
plt.title('Target vs Dependency')
-
약한 음의 상관관계를 보임
-
dependency가 증가할수록target값이 감소함 -
dependency가 (dependent)/(non-dependent)를 나타냄을 의미 -
해당 값이 증가하면, 빈곤의 심각성이 증가하는 경향이 있음
-
(보통 일을 하지 않는) 의존적인 가족 구성원은 비의존적인 가족 구성원의 지원을 받아야 함 => 더 높은 수준의 빈곤으로 이어짐
sns.lmplot(x = 'rooms-per-capita', y = 'Target', fit_reg = True, data = train_heads,
x_jitter = 0.05, y_jitter = 0.05)
plt.title('Target vs Rooms Per Capita')
- 약한 양의 상관관계를 보임
📌상관계수 heatmap
- 상관계수 시각화
# Household Variables
variables = ['Target', 'dependency', 'warning', 'walls+roof+floor', 'meaneduc',
'floor', 'r4m1', 'overcrowding']
# 상관계수 계산
corr_mat = train_heads[variables].corr().round(2)
# heatmap 생성
plt.rcParams['font.size'] = 18
plt.figure(figsize = (12, 12))
sns.heatmap(corr_mat, vmin = -0.5, vmax = 0.8, center = 0,
cmap = plt.cm.RdYlGn_r, annot = True);
-
target과 약한 상관관계를 가지는 변수들이 상당수 존재함을 보여줌
-
일부 변수들의 경우 변수들 간의 상관도가 높음
-
floorvswalls+roof+floor -
다중공선성(multicollinearity) 문제
-
b) 변수 시각화
- 위쪽 삼각형에는 산점도(scatterplot), 대각선에는 커널 밀도 plot(KDE), 아래쪽 삼각형에는 2차원 KDE 그림을 표시해보자!
import warnings
warnings.filterwarnings('ignore')
# 시각화 할 변수 선택
plot_data = train_heads[['Target', 'dependency', 'walls+roof+floor',
'meaneduc', 'overcrowding']]
# 영역 나누기 -> pairgrid
grid = sns.PairGrid(data = plot_data, diag_sharey = False,
hue = 'Target', hue_order = [4, 3, 2, 1],
vars = [x for x in list(plot_data.columns) if x != 'Target'])
# Upper: scatter plot
grid.map_upper(plt.scatter, alpha = 0.8, s = 20)
# Diagonal: kdeplot
grid.map_diag(sns.kdeplot)
# Bottom: 2차원 kdeplot
grid.map_lower(sns.kdeplot, cmap = plt.cm.OrRd_r)
grid = grid.add_legend()
plt.suptitle('Feature Plots Colored By Target', size = 32, y = 1.05)
household_feats = list(heads.columns) # 가구 수준에서의 변수들을 최종적으로 저장
3-5. Individual Level Variables
-
두 가지 유형이 존재함
-
boolean형 변수(1 or 0)
-
순서형(ordinal) 변수(의미 있는 순서가 지정된 개별 값)
-
ind = data[id_ + ind_bool + ind_ordered]
ind.shape
a) 중복 변수 제거하기
- 상관 계수의 절댓값이 0.95보다 큰 변수에 주목하자.
# 상관계수 행렬 생성
corr_matrix = ind.corr()
# 상삼각행렬만 남기기
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k = 1).astype(np.bool))
# 상관계수가 0.95 이상인 변수들
to_drop = [column for column in upper.columns if any(abs(upper[column]) > 0.95)]
to_drop
-
이는 단순히 남성의 반대를 의미
- 남성 flag 변수를 제거
ind = ind.drop(columns = 'male')
b) 순서형 변수 생성하기
-
기존의 변수들을 순서형 변수로 매핑 가능
- 개인의 교육 수준을 나타내는
instlevel_변수를 중심으로 1(교육 수준이 x)부터 9(대학원)까지 mapping
- 개인의 교육 수준을 나타내는
ind[[c for c in ind if c.startswith('instl')]].head()
ind['inst'] = np.argmax(np.array(ind[[c for c in ind if c.startswith('instl')]]), axis = 1)
plot_categoricals('inst', 'Target', ind, annotate = False);
- 더 높은 수준의 교육을 받을수록 덜 극단적인 수준의 빈곤에 해당하는 것으로 보임
plt.figure(figsize = (10, 8))
sns.violinplot(x = 'Target', y = 'inst', data = ind)
plt.title('Education Distribution by Target');
# Drop the education columns
# ind = ind.drop(columns = [c for c in ind if c.startswith('instlevel')])
ind.shape
c) 새로운 변수 생성하기
- 기존 데이터를 사용하여 몇 가지 변수들을 만들 수 있음
ind['escolari/age'] = ind['escolari'] / ind['age']
plt.figure(figsize = (10, 8))
sns.violinplot(x = 'Target', y = 'escolari/age', data = ind)
ind['inst/age'] = ind['inst'] / ind['age']
ind['tech'] = ind['v18q'] + ind['mobilephone']
ind['tech'].describe()
3-6. 변수 집계
-
개별 데이터를 가구 데이터에 통합하기 위해서는 가구별 집계가 필요
- 가족 ID인
idhogar로 그룹화 후 데이터를agg로 그룹화
- 가족 ID인
### 집계(aggregation)를 위한 사용자 정의 함수
range_ = lambda x: x.max() - x.min() # 한 줄짜리 함수는 주로 lambda 식으로 구현
range_.__name__ = 'range_'
# 그룹화 & 집계
ind_agg = ind.drop(columns = ['Target','Id']).groupby('idhogar').agg(['min', 'max', 'sum', 'count', 'std', range_])
ind_agg.head()
- 변수가 30개에서 180개가 되었다..
### 변수 이름 재정의
new_col = []
for c in ind_agg.columns.levels[0]:
for stat in ind_agg.columns.levels[1]:
new_col.append(f'{c}-{stat}')
ind_agg.columns = new_col
ind_agg.head()
ind_agg.iloc[:, [0, 1, 2, 3, 6, 7, 8, 9]].head()
3-7. 변수 선택
- 상관 관계가 0.95보다 큰 변수들의 쌍 중 하나를 제거
# Create correlation matrix
corr_matrix = ind_agg.corr()
# Select upper triangle of correlation matrix
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(np.bool))
# Find index of feature columns with correlation greater than 0.95
to_drop = [column for column in upper.columns if any(abs(upper[column]) > 0.95)]
print(f'There are {len(to_drop)} correlated columns to remove.')
- 변수를 제거하고,
head데이터와 병합하여 최종 데이터프레임을 생성
ind_agg = ind_agg.drop(columns = to_drop)
ind_feats = list(ind_agg.columns)
# Merge on the household id
final = heads.merge(ind_agg, on = 'idhogar', how = 'left')
print('Final features shape: ', final.shape)
final.head()
3-8. 최종적인 데이터 탐색
a) 상관계수 확인
corrs = final.corr()['Target']
corrs.sort_values().head()
corrs.sort_values().dropna().tail()
-
생성된 변수 중 일부가 target 변수와 높은 상관관계를 가지고 있다는 것을 확인할 수 있음
-
해당 변수가 실제로 유용한지는 모델링 단계에서 판단할 예정
b) escolari 변수
plot_categoricals('escolari-max', 'Target', final, annotate = False)
plt.figure(figsize = (10, 6))
sns.violinplot(x = 'Target', y = 'escolari-max', data = final)
plt.title('Max Schooling by Target')
plt.figure(figsize = (10, 6))
sns.boxplot(x = 'Target', y = 'escolari-max', data = final)
plt.title('Max Schooling by Target')
c) meaneduc 변수
plt.figure(figsize = (10, 6))
sns.boxplot(x = 'Target', y = 'meaneduc', data = final)
plt.xticks([0, 1, 2, 3], poverty_mapping.values())
plt.title('Average Schooling by Target')
d) Overcrowing 변수
plt.figure(figsize = (10, 6))
sns.boxplot(x = 'Target', y = 'overcrowding', data = final)
plt.xticks([0, 1, 2, 3], poverty_mapping.values())
plt.title('Overcrowding by Target')
e) 가장의 성별
head_gender = ind.loc[ind['parentesco1'] == 1, ['idhogar', 'female']]
final = final.merge(head_gender, on = 'idhogar', how = 'left').rename(columns = {'female': 'female-head'})
final.groupby('female-head')['Target'].value_counts(normalize=True)
- 가장이 여성인 가구는 빈곤 수준아 심각할 가능성이 약간 더 높은 것으로 보인다.
sns.violinplot(x = 'female-head', y = 'Target', data = final)
plt.title('Target by Female Head of Household');
가장의 성별에 따른 평균 교육 수준 차이
plt.figure(figsize = (8, 8))
sns.boxplot(x = 'Target', y = 'meaneduc', hue = 'female-head', data = final)
plt.title('Average Education by Target and Female Head of Household', size = 16)
-
여성 가장을 둔 가구일수록 교육 수준이 높은 것으로 보임
-
그러나 전체적으로 여성이 가장인 가구는 심각한 빈곤을 겪을 가능성이 더 높다는 것을 알 수 있음
final.groupby('female-head')['meaneduc'].agg(['mean', 'count'])
- 전체적으로 여성 가장이 있는 가구의 평균 교육 수준은 남성 가장이 있는 가구보다 약간 높음
4. Baseline Model
-
모든 데이터(train/test)는 각 가구에 대해 집계되므로 모델에 직접 사용할 수 있음
-
sklearn의
RandomForest를 활용하여 모델링 기준 찾기 -
모델을 평가하기 위해 train 데이터에
10-fold 교차 검증을 활용- 데이터를 서로 다른 데이터 집합으로 분할하여 모델을 총 10번 훈련
-
교차 검증의 평균 성능과 표준 편차를 조사하여 fold 간에 점수가 얼마나 변하는지 확인
Fl Macro Score를 사용하여 성능 평가
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score, make_scorer
from sklearn.model_selection import cross_val_score
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import MinMaxScaler
from sklearn.pipeline import Pipeline
# 교차 검증을 위해 사용자 정의 함수 만들기
scorer = make_scorer(f1_score, greater_is_better=True, average = 'macro')
# 학습을 위한 label(target) 값
train_labels = np.array(list(final[final['Target'].notnull()]['Target'].astype(np.uint8)))
# train/ test set 준비
train_set = final[final['Target'].notnull()].drop(columns = ['Id', 'idhogar', 'Target'])
test_set = final[final['Target'].isnull()].drop(columns = ['Id', 'idhogar', 'Target'])
# 제출용 양식 만들기
submission_base = test[['Id', 'idhogar']].copy()
4-1. Pipelining
-
여러 모형을 비교하기 위해 feature들 간의 스케일을 조정
-
각 컬럼(변수)의 범위를
0과 1 사이로 제한 -
많은 앙상블 모델의 경우 불필요하지만, KNearest Neighbors 또는 Support Vector Machine과 같이 거리 메트릭에 의존하는 모델을 사용할 경우
feature scaling이절대적으로 필요 -
결측치의 경우 feature의 중앙값으로 대체
-
-
결측치를 처리하고 feature들을 한 번에 scaling 하기 위해
Pipeline을 만들 수 있음- train 데이터를 모델에 적합하고 train 및 test 데이터를 변환하는 데 사용
features = list(train_set.columns)
pipeline = Pipeline([('imputer', SimpleImputer(strategy = 'median')),
('scaler', MinMaxScaler())])
# 데이털를 알맞게 변환(전처리)
train_set = pipeline.fit_transform(train_set)
test_set = pipeline.transform(test_set)
-
데이터에는 결측값이 없으며, 0과 1 사이 범위로 scaling 됨
- scikit-Learn 모델에서 직접 사용할 수 있음
### 모델 학습
model = RandomForestClassifier(n_estimators = 100, random_state = 10, n_jobs = -1)
# 10 fold cross validation
cv_score = cross_val_score(model, train_set, train_labels, cv = 10, scoring = scorer)
print(f'10 Fold Cross Validation F1 Score = {round(cv_score.mean(), 4)} with std = {round(cv_score.std(), 4)}')
- 현재는 성능이 그다지 좋지는 않음
4-2. 피쳐 중요도 확인
-
트리 기반 모델을 사용하면 모델의 기능 유용성에 대한 상대적 순위를 보여주는
기능 중요도(feature importances)를 살펴볼 수 있음-
분할을 위해 변수를 사용한 노드의 불순물 감소의 합을 의미
-
상대 점수에 초점
-
-
feature importances를 보기 위해선 전체 train 데이터에 대해 모델을 train시켜야 함 -
교차 검증의 경우 feature importance를 반환하지 x
model.fit(train_set, train_labels) # 전체 데이터에 대해 학습
# Feature importances 확인
feature_importances = pd.DataFrame({'feature': features, 'importance': model.feature_importances_})
feature_importances.head()
📌 기능 중요도 시각화 함수
-
중요한 순서대로 n개의 피쳐 시각화
-
임계값(threshold)이 지정된 경우 누적 중요도를 표시하고, 누적 중요도가 임계값에 도달하는 데 필요한 피쳐 수를 print
-
트리 기반 기능 중요도와 함께 사용하도록 설계됨
-
Arguments>
-
df(dataframe)-
피처 중요도의 데이터 프레임
-
열은 기능 및 중요도여야 함
-
-
n(int)-
중요도 순으로 표시할 피쳐 수
-
default = 15
-
-
threshold(float)-
누적 중요도 plot의 임계값
-
임계값이 제공되지 않으면 plot이 생성되지 x
-
default: None
-
-
-
Returns>
-
df(dataframe)- 정규화된 컬럼(합계 = 1)과 누적 중요도 컬럼을 사용하여 피쳐 중요도 순으로 정렬된 데이터 프레임
-
(Note)
-
이 경우 정규화는 합이 1이라는 것을 의미
-
누적 중요도는 가장 중요하지 않은 feature부터 가장 중요하지 않은 feature를 합산하여 계산
-
threshold = 0.9: 누적 중요도의 90%에 도달하는 데 필요한 가장 중요한 feature를 표시
def plot_feature_importances(df, n = 10, threshold = None):
plt.style.use('fivethirtyeight')
# 가장 중요한 기능 기준 내림차순 정렬
df = df.sort_values('importance', ascending = False).reset_index(drop = True)
# 피쳐 중요도를 정규화(0 ~ 1 사이)하여 누적 중요도 계산
df['importance_normalized'] = df['importance'] / df['importance'].sum()
df['cumulative_importance'] = np.cumsum(df['importance_normalized'])
plt.rcParams['font.size'] = 12
# 중요한 순서대로 n개 feature에 대한 barhplot
df.loc[:n, :].plot.barh(y = 'importance_normalized',
x = 'feature', color = 'darkgreen',
edgecolor = 'k', figsize = (12, 8),
legend = False, linewidth = 2)
plt.xlabel('Normalized Importance', size = 18); plt.ylabel('');
plt.title(f'{n} Most Important Features', size = 18)
plt.gca().invert_yaxis()
### ------------------------------------------------------------------------
# 임계값에 다다랐다면
if threshold:
# 누적 중요도 plot
plt.figure(figsize = (8, 6))
plt.plot(list(range(len(df))), df['cumulative_importance'], 'b-')
plt.xlabel('Number of Features', size = 16); plt.ylabel('Cumulative Importance', size = 16)
plt.title('Cumulative Feature Importance', size = 18)
# 누적 중요도에 도달하기 위한 feature 수
# 인덱스(-> 실제 숫자에 대해 1을 추가해야 함)
importance_index = np.min(np.where(df['cumulative_importance'] > threshold))
# 수직 선 추가
plt.vlines(importance_index + 1, ymin = 0, ymax = 1.05, linestyles = '--', colors = 'red')
plt.show()
print('{} features required for {:.0f}% of cumulative importance.'.format(importance_index + 1,
100 * threshold))
return df
norm_fi = plot_feature_importances(feature_importances, threshold=0.95)
-
가장 중요한 변수는
meaneduc(가구 내 평균 교육량)이고, 다음이age-max(가구 내 한 개인의 최대 교육량)임-
이 두 변수는 상관성이 높은 변수들임
-
따라서, 데이터에서 변수 중 하나를 제거해야 한다는 것을 의미
-
-
다른 중요한 feature들은 우리가 만든 변수와 데이터에 이미 존재했던 변수들과의 조합으로 생성된 변수들임
-
90%의 중요도를 위해서는 대략 180개 정도의 feature들만 존재해도 ok
- 일부 feature들을 제거해도 무방함
-
피처 중요도은 피처가 어느 방향으로 중요한지를 알려주지는 않음
-
예를 들어, 교육을 많이 받을수록 덜 심각한 빈곤으로 이어지는지를 알려주지는 못함
-
관련이 있을 것으로 간주되는 모델만 알려줌
-
### 커널 밀도 함수 시각화
# "variable" 별로 "target" 값의 분포를 표시
def kde_target(df, variable):
colors = {1: 'red', 2: 'orange', 3: 'blue', 4: 'green'}
plt.figure(figsize = (12, 8))
df = df[df['Target'].notnull()]
for level in df['Target'].unique():
subset = df[df['Target'] == level].copy()
sns.kdeplot(subset[variable].dropna(),
label = f'Poverty Level: {level}',
color = colors[int(subset['Target'].unique())])
plt.xlabel(variable); plt.ylabel('Density');
plt.title('{} Distribution'.format(variable.capitalize()));
kde_target(final, 'meaneduc')
kde_target(final, 'escolari/age-range_')
4-2. 모델 선택
-
이미 RandomForestClassifier는 시도
- Macro F1-score: 0.35
-
기계 학습에서는 어떤 모델이 주어진 데이터 세트에 가장 잘 작동하는지 미리 알 수 있는 방법이 없음
-
각 상황마다 다름..
-
어떤 것이 최적인지 확인하기 위해서는 여러 가지 모델을 시도해 보아야 함
-
# Model imports
from sklearn.svm import LinearSVC
from sklearn.naive_bayes import GaussianNB
from sklearn.neural_network import MLPClassifier
from sklearn.linear_model import LogisticRegressionCV, RidgeClassifierCV
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import ExtraTreesClassifier
import warnings
from sklearn.exceptions import ConvergenceWarning
# Filter out warnings from models
warnings.filterwarnings('ignore', category = ConvergenceWarning)
warnings.filterwarnings('ignore', category = DeprecationWarning)
warnings.filterwarnings('ignore', category = UserWarning)
# 결과 저장을 위한 data frame
model_results = pd.DataFrame(columns = ['model', 'cv_mean', 'cv_std'])
📌 모델 평가를 위한 함수
-
RandomForestClassifier외에 8개의 다른 Scikit - Learn 모델 사용 -
결과를 저장할 데이터 프레임을 만들고, 함수는 각 모델의 데이터 프레임에 행을 추가하는 작업을 수행
-
각 모델에 대해 10-fold 교차 검증 수행
def cv_model(train, train_labels, model, name, model_results = None):
cv_scores = cross_val_score(model, train, train_labels, cv = 10, scoring=scorer, n_jobs = -1)
print(f'10 Fold CV Score: {round(cv_scores.mean(), 5)} with std: {round(cv_scores.std(), 5)}')
if model_results is not None:
# 결과 저장
model_results = model_results.append(pd.DataFrame({'model': name,
'cv_mean': cv_scores.mean(),
'cv_std': cv_scores.std()},
index = [0]),ignore_index = True)
return model_results
### 1. Linear SVC
model_results = cv_model(train_set, train_labels,
LinearSVC(), 'LSVC', model_results)
-
성능이 그닥 좋지 않음
- 목록에서 삭제할 수 있는 모델 중 하나
### 2. Gaussian Naive Bayes
model_results = cv_model(train_set, train_labels,
GaussianNB(), 'GNB', model_results)
- 매우 나쁜 성능..
### 3. Multi-Layer Perceptron
model_results = cv_model(train_set, train_labels,
MLPClassifier(hidden_layer_sizes=(32, 64, 128, 64, 32)),
'MLP', model_results)
-
괜찮은 성능을 보이고 있음
-
하이퍼파라미터를 사용하여 네트워크를 조정할 수 있는 경우 해당 모델을 사용할 수 있음
-
하지만 제한된 양의 데이터는 일반적으로 효과적인 학습을 위해선 수십만 개의 예제를 필요로 하기 때문에 신경망에 문제가 될 수 있음
-
### 4. LinearDiscriminantAnalysis
model_results = cv_model(train_set, train_labels,
LinearDiscriminantAnalysis(),
'LDA', model_results)
-
UserWarning을 filtering하지 않고 LDA를 진행 시 에러 발생
Variables are collinear.: 공선성 문제
-
선형 변수를 제거한 후 해당 모델을 다시 시도해 볼 수 있음
### 5. Ridge
model_results = cv_model(train_set, train_labels,
RidgeClassifierCV(), 'RIDGE', model_results)
-
선형 모형(ridge 모델 포함)은 놀라울 정도로 잘 작동함
- 단순한 모델이 이 문제에서는 더 도움이 될 수도 있음을 의미
### 6. K-Neighbors
for n in [5, 10, 20]:
print(f'\nKNN with {n} neighbors\n')
model_results = cv_model(train_set, train_labels,
KNeighborsClassifier(n_neighbors = n),
f'knn-{n}', model_results)
### 7. ExtraTreeClassifier
model_results = cv_model(train_set, train_labels,
ExtraTreesClassifier(n_estimators = 100, random_state = 10),
'EXT', model_results)
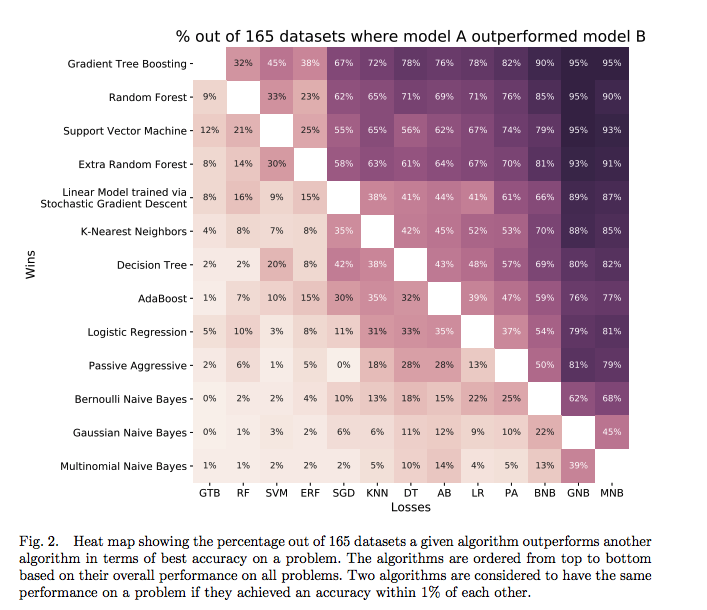
4-3. 모델 성능 비교
- 모델링 결과가 저장된 df를 활용해 어떤 모델이 가장 효과적인지 시각화하는 그래프를 그릴 수 있음
# 처음으로 수행한 RandomForestClassifier의 결과도 저장해주기
model_results = cv_model(train_set, train_labels,
RandomForestClassifier(100, random_state=10),
'RF', model_results)
### 모델링 결과 시각화
model_results.set_index('model', inplace = True)
model_results['cv_mean'].plot.bar(color = 'orange', figsize = (8, 6),
yerr = list(model_results['cv_std']),
edgecolor = 'k', linewidth = 2)
plt.title('Model F1 Score Results')
plt.ylabel('Mean F1 Score (with error bar)')
model_results.reset_index(inplace = True)
-
RandomForestClassifier는 가장 간단하게 사용할 수 있기에, 가장 먼저 시도해 볼 수 있는 모형임 -
아직 baseline model들의 경우 하이퍼 파라미터를 조정하지 않아 모델 간 비교가 완벽하지는 않지만, 트리 기반 앙상블 방법(
Gradient Boosting Machine포함)이 구조화된 데이터 세트에서 매우 잘 수행된다는 다른 많은 Kaggle competition의 결과를 반영하고 있음
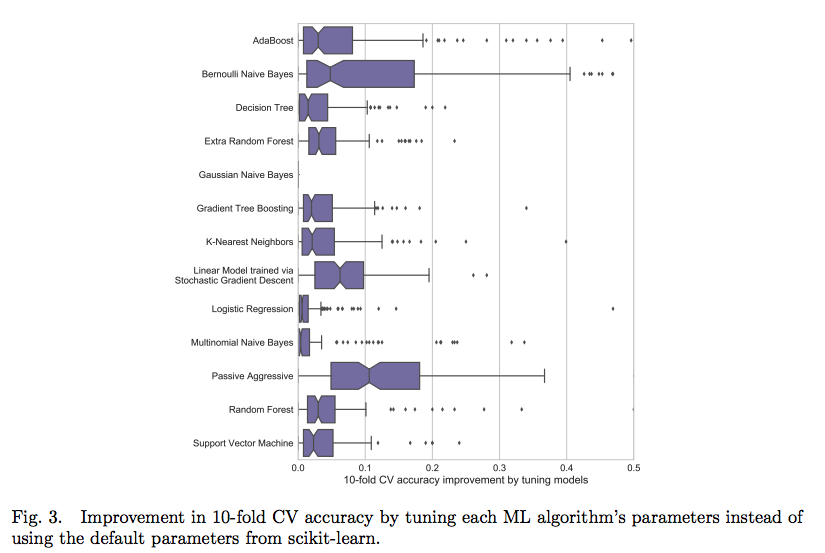
하이퍼 파라미터 조정 효과
-
대부분의 경우 정확도 향상은 10% 미만
- 최악의 모델은 튜닝을 통해 갑자기 최고의 모델이 되지는 않을 것임
-
일단은 그냥 RandomForestClassifier로 예측 수행
4-4. 제출 파일 생성
-
제출하기 위해서는 test 데이터가 필요함
- 현재 test data가 train data와 같은 방식으로 format 되어 있음
-
가구별로 예측을 하고 있지만 실제로는 개인당 한 줄(Id로 식별)만 필요
- 가장(household)에 대한 예측만 점수가 매겨짐
-
테스트 제출 형식
Id,Target
ID_2f6873615,1
ID_1c78846d2,2
ID_e5442cf6a,3
ID_a8db26a79,4
ID_a62966799,4
-
submission_base는 각 개인에 대한 예측이 있어야 함submission_base는 모든 개인을 test set에 포함
-
test_ids: 가장의idhogar만 포함 -
예측 시에는 각 가구에 대해서만 예측한 다음 예측 데이터 프레임을 가구 ID(
idhogar)의 모든 개인과 병합-
target이 가구원 모두에게 동일한 값으로 설정됨 -
가장이 없는 가구의 경우 점수가 매겨지지 않으므로 이러한 경우에는 예측치를 4(non-vulnerable)로 설정
-
test_ids = list(final.loc[final['Target'].isnull(), 'idhogar'])
📌 예측을 위한 함수
-
모델, train 세트, train label 및 test 세트를 가져와 다음 작업들을 수행
-
fit()을 활용하여 train 데이터에 대해 모델을 학습 -
predict()를 활용하여 test 데이터로 예측 -
이를 저장하여 제출 파일로 만들 수 있도록 submission 데이터 프레임 생성
-
def submit(model, train, train_labels, test, test_ids):
model.fit(train, train_labels) # 학습
predictions = model.predict(test) # 예측
predictions = pd.DataFrame({'idhogar': test_ids,
'Target': predictions})
# 제출용 df 만들기
submission = submission_base.merge(predictions,
on = 'idhogar',
how = 'left').drop(columns = ['idhogar'])
# 가장 x -> 4로 채우기
submission['Target'] = submission['Target'].fillna(4).astype(np.int8)
return submission
### RandomForest로 예측
rf_submission = submit(RandomForestClassifier(n_estimators = 100,
random_state=10, n_jobs = -1),
train_set, train_labels, test_set, test_ids)
rf_submission.to_csv('rf_submission.csv', index = False)
- 예측 성능: 0.370
4-5. 변수 선택
-
모델 성능을 향상시키는 한 가지 방법
- 모델에 가장 유용한 기능만 유지하려고 하는 프로세스
-
해당 노트북에서는 feature를 선택하는 경우 먼저 상관 관계가 0.95보다 큰 열을 제거한 다음, scikit-learn 라이브러리를 활용하여 중복적인 feature 제거를 적용
a) 상관도가 높은 변수 제거
- 상관계수가 0.95 이상인 변수들을 제거
### 상관계수가 0.95 이상인 컬럼 확인
train_set = pd.DataFrame(train_set, columns = features)
# 상관계수 행렬 생성
corr_matrix = train_set.corr()
# 상삼각행렬만 선택
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(np.bool))
# 상관계수가 0.95 이상인 컬럼만 선택
to_drop = [column for column in upper.columns if any(abs(upper[column]) > 0.95)]
to_drop
# 해당 컬럼 drop
train_set = train_set.drop(columns = to_drop)
train_set.shape
# test data에서도 해당 feature들을 제거
test_set = pd.DataFrame(test_set, columns = features)
train_set, test_set = train_set.align(test_set, axis = 1, join = 'inner')
features = list(train_set.columns)
b) RandomForest를 활용하여 중복 변수 제거
-
sklearn.RFECV-
교차 검증을 통한 중복적인 feature 제거를 의미
-
반복적인 방식으로 피처 중요도가 있는 모델을 사용
-
각 반복마다 피처의 일부 또는 설정된 개수의 피처를 제거
-
교차 검증 점수가 더 이상 향상되지 않을 때까지 작업을 계속 반복함
-
-
selector 객체를 만들기 위해 모델, 각 반복마다 제거할 feature의 수, 교차 검증 시의 fold 수, 사용자 지정 점수 계산기 및 선택을 안내하는 기타 parameter들을 설정
from sklearn.feature_selection import RFECV
# 변수 선택을 위한 모델 객체 생성
estimator = RandomForestClassifier(random_state = 10, n_estimators = 100, n_jobs = -1)
# selector 객체 생성
selector = RFECV(estimator, step = 1, cv = 3, scoring = scorer, n_jobs = -1)
### 학습
selector.fit(train_set, train_labels)
### 결과 시각화
plt.plot(selector.cv_results_.keys())
plt.xlabel('Number of Features'); plt.ylabel('Macro F1 Score'); plt.title('Feature Selection Scores');
selector.n_features_
-
최대 96개의 변수를 추가하면 점수가 향상된다는 것을 확인할 수 있음
- selector에 따르면 이것이 최적의 feature 개수임
-
각 feature의 순위는 훈련된 selector 객체를 통해 확인할 수 있음
-
여러 번의 반복에 걸처 평균화된 기능 중요도를 표시
-
순위가 동일할 수 있으며, 순위가 1인 feature만 유지됨
-
rankings = pd.DataFrame({'feature': list(train_set.columns), 'rank': list(selector.ranking_)}).sort_values('rank')
rankings.head(10)
최종 변수 선택 & 교차 검증 수행
train_selected = selector.transform(train_set)
test_selected = selector.transform(test_set)
# df로 재가공
selected_features = train_set.columns[np.where(selector.ranking_==1)]
train_selected = pd.DataFrame(train_selected, columns = selected_features)
test_selected = pd.DataFrame(test_selected, columns = selected_features)
model_results = cv_model(train_selected, train_labels, model, 'RF-SEL', model_results)
# 결과 시각화
model_results.set_index('model', inplace = True)
model_results['cv_mean'].plot.bar(color = 'orange', figsize = (8, 6),
yerr = list(model_results['cv_std']),
edgecolor = 'k', linewidth = 2)
plt.title('Model F1 Score Results');
plt.ylabel('Mean F1 Score (with error bar)');
model_results.reset_index(inplace = True)
- feature selection 한 모델이 교차 검증에서 약간 더 우수한 성능을 보임
5. 모델 업데이트
5-1. Light Gradient Boosting Machine
-
Kaggle 대회에서 주로 데이터기 구조화되어 있고(테이블 형태), 데이터 셋이 그리 크지 않은 경우(관측치가 백만 개 미만)
GBM(Gradient Boosting Machine)이 경쟁에서 높은 비율로 승리함 -
Gradient Boosting Machine을 위한 하이퍼 파라미터 최적화는 주로 모델 최적화를 통해 수행됨
- 이전에 잘 작동하였던 값들을 기준으로 하이퍼 파라미터를 설정함
-
n_estimators를 일단 10000으로 설정하였지만, 해당 숫자에 도달하지는 못함-
우리는
early_stopping_rounds를 설정함-
교차 검증 metric이 개선되지 않을 때 train estimator를 종료시킴
-
display는%%capture와 결합하여 train 중 사용자 지정 정보를 보여주기 위해 사용됨
-
-
📌 조기 종료(Early Stopping)를 통한 estimator의 개수 정하기
-
estimator의 수(
n_estimators또는num_boost_rounds라고 하는 앙상블의 의사 결정 트리 수)를 선택하기 위해 5-fold 교차 검증을 활용하여 조기 중지 수행-
Macro F1-score로 측정한 성능이 100회의 train 라운드 동안 증가하지 않을 때까지 추정치를 계속 추가할 수 있음
-
해당 metric을 사용하기 위해서는 사용자 지정 metric을 정의해야 함
-
def macro_f1_score(labels, predictions):
predictions = predictions.reshape(len(np.unique(labels)), -1).argmax(axis = 0)
metric_value = f1_score(labels, predictions, average = 'macro')
return 'macro_f1', metric_value, True
📌 Stratified K-Fold를 위한 함수
-
Stratified K-fold 교차 검증 및 조기 정지를 통해 그레이디언트 부스팅 머신을 교육
-
교육 데이터에 과적합되는 것을 방지
-
교차 검증을 통해 학습을 수행하고 각 fold에 대한 확률로 예측을 기록
-
각 fold의 예측값을 반환한 다음 제출물을 반환하여 결과 확인
from sklearn.model_selection import StratifiedKFold
import lightgbm as lgb
from IPython.display import display
def model_gbm(features, labels, test_features, test_ids,
nfolds = 5, return_preds = False, hyp = None):
feature_names = list(features.columns) # 변수들을 저장
### 사용자 지정 hyper parameter에 대한 옵션
# 사용자 지정 hyper parameter가 있는 경우
if hyp is not None:
# early sropping을 사용하므로 estimator 수가 필요하지 않음
if 'n_estimators' in hyp:
del hyp['n_estimators']
params = hyp
else:
# 기본 하이퍼 파라미터 설정
params = {'boosting_type': 'dart',
'colsample_bytree': 0.88,
'learning_rate': 0.028,
'min_child_samples': 10,
'num_leaves': 36, 'reg_alpha': 0.76,
'reg_lambda': 0.43,
'subsample_for_bin': 40000,
'subsample': 0.54,
'class_weight': 'balanced'}
# 모델 객체 생성
model = lgb.LGBMClassifier(**params, objective = 'multiclass',
n_jobs = -1, n_estimators = 10000,
random_state = 10)
# Stratified k-Fold 교차 검증
strkfold = StratifiedKFold(n_splits = nfolds, shuffle = True)
# 각 fold마다 예측한 결과를 저장
predictions = pd.DataFrame()
importances = np.zeros(len(feature_names))
# 인덱싱을 위해 array로 변환
features = np.array(features)
test_features = np.array(test_features)
labels = np.array(labels).reshape((-1 ))
valid_scores = [] # 검증 점수
### 각 fold 마다
for i, (train_indices, valid_indices) in enumerate(strkfold.split(features, labels)):
# 각 fold마다 예측 수행 -> 결과 저장
fold_predictions = pd.DataFrame()
# train data / valid data
X_train = features[train_indices]
y_train = labels[train_indices]
X_valid = features[valid_indices]
y_valid = labels[valid_indices]
# 학습(early stopping 적용)
model.fit(X_train, y_train, early_stopping_rounds = 100,
eval_metric = macro_f1_score,
eval_set = [(X_train, y_train), (X_valid, y_valid)],
eval_names = ['train', 'valid'],
verbose = 200)
# 검증 점수 저장
valid_scores.append(model.best_score_['valid']['macro_f1'])
# "확률"을 통한 예측 수행
fold_probabilitites = model.predict_proba(test_features)
# 개별 컬럼으로 예측값 저장
for j in range(4):
fold_predictions[(j + 1)] = fold_probabilitites[:, j]
# 예측을 위해 필요한 정보 추가
fold_predictions['idhogar'] = test_ids
fold_predictions['fold'] = (i+1)
# 예측을 기존 예측에 새 행으로 추가
predictions = predictions.append(fold_predictions)
# 각 fold 별 피처 중요도
importances += model.feature_importances_ / nfolds
# fold에 대한 정보 표시
display(f'Fold {i + 1}, Validation Score: {round(valid_scores[i], 5)}, Estimators Trained: {model.best_iteration_}')
# 피쳐 중요도를 df로 저장
feature_importances = pd.DataFrame({'feature': feature_names,
'importance': importances})
# 검증 점수에 대한 정보 표시
valid_scores = np.array(valid_scores)
display(f'{nfolds} cross validation score: {round(valid_scores.mean(), 5)} with std: {round(valid_scores.std(), 5)}.')
# 예측이 평균을 초과하지 않는지 확인하려면
if return_preds:
predictions['Target'] = predictions[[1, 2, 3, 4]].idxmax(axis = 1)
predictions['confidence'] = predictions[[1, 2, 3, 4]].max(axis = 1)
return predictions, feature_importances
# fold 별 예측을 평균
predictions = predictions.groupby('idhogar', as_index = False).mean()
# 클래스 및 관련 확률 찾기
predictions['Target'] = predictions[[1, 2, 3, 4]].idxmax(axis = 1)
predictions['confidence'] = predictions[[1, 2, 3, 4]].max(axis = 1)
predictions = predictions.drop(columns = ['fold'])
# 각 개체에 대해 "하나"의 예측값을 갖도록 기존의 값과 병합
submission = submission_base.merge(predictions[['idhogar', 'Target']],
on = 'idhogar', how = 'left').drop(columns = ['idhogar'])
# 결측치 -> class = 4로 채우기
# 점수 계산이 되지 x
submission['Target'] = submission['Target'].fillna(4).astype(np.int8)
return submission, feature_importances, valid_scores
a) 조기 중지 노트를 사용한 교차 검증
-
train 세트에서 과적합을 방지하는 가장 효과적인 방법 중 하나
- 검증 점수가 개선되지 않는 것이 분명해지면 모델 복잡성을 늘릴 수 없기 때문
-
해당 과정을 여러 fold에서 반복하면 단일 fold를 사용할 때 발생될 수 있는 편향(bias)을 줄이는 데 도움이 됨
-
또한, 빠른 학습 가능
-
Gradient Boosting Machine에서 eatimator의 수를 선택하는 가장 좋은 방법
%%capture --no-display
predictions, gbm_fi = model_gbm(train_set, train_labels, test_set, test_ids, return_preds=True)
- LGBM을 활용하여 교차 검증을 수행한 결과 성능이 많이 높아짐
### 예측값 확인
predictions.head()
-
각 fold에 대해 1, 2, 3, 4열은 각 target에 대한
확률을 나타냄- target로 confidence가 최대치인 것을 선택
-
5개의 fold 모두에 대한 예측을 가지고 있음
- 다른 fold에 대한 각 target에 대한 신뢰도 표시 가능
plt.rcParams['font.size'] = 18
### Kdeplot
g = sns.FacetGrid(predictions, row = 'fold', hue = 'Target', aspect = 4)
g.map(sns.kdeplot, 'confidence');
g.add_legend();
plt.suptitle('Distribution of Confidence by Fold and Target', y = 1.05);
-
각 클래스에 대한 신뢰도가 상대적으로 낮음
- 클래스 불균형과 높은 보급률로 인해
Target = 4에 대한 신뢰도가 높은 것으로 보임
- 클래스 불균형과 높은 보급률로 인해
### violinplot
plt.figure(figsize = (24, 12))
sns.violinplot(x = 'Target', y = 'confidence', hue = 'fold', data = predictions)
-
불균형 클래스임을 확인할 수 있음
-
모델이 각각의 클래스를 구분하는 데 어려움을 겪을 수 있음
-
이후 예측치를 보고 혼란을 야기하는 위치를 탐색할 수 있음
-
-
각 가구별 예측 수행 시 각 fold에 대한 예측값을
평균함- 각각의 모델은 약간씩 다른 데이터 fold에 대해 학습됨 -> 여러 모델을 사용함
-
Gradient Boosting Machine은
앙상블 모델이며, 여러 gbm 모델을 활영하여meta-ensemble로 활용
# fold 별 예측을 평균
predictions = predictions.groupby('idhogar', as_index = False).mean()
# 클래스 및 관련 확률 찾기
predictions['Target'] = predictions[[1, 2, 3, 4]].idxmax(axis = 1)
predictions['confidence'] = predictions[[1, 2, 3, 4]].max(axis = 1)
predictions = predictions.drop(columns = ['fold'])
# 각 target에 대한 신뢰도 plotting
plt.figure(figsize = (10, 6))
sns.boxplot(x = 'Target', y = 'confidence', data = predictions)
plt.title('Confidence by Target')
plt.figure(figsize = (10, 6))
sns.violinplot(x = 'Target', y = 'confidence', data = predictions)
plt.title('Confidence by Target')
-
5개의 fold에 대한 평균 예측을 취하며, 사실상 5개의 서로 다른 모델을 결합하는 것과 동일
-
각 모델은 약간씩 다른 데이터 부분 집합에 대해서 학습됨
%%capture
submission, gbm_fi, valid_scores = model_gbm(train_set, train_labels,
test_set, test_ids, return_preds=False)
submission.to_csv('gbm_baseline.csv')
### feature 중요도 확인
_ = plot_feature_importances(gbm_fi, threshold = 0.95)
-
gbm에서 중요하게 작용하는 feature들은 주로
age(나이)에서 파생된 feature들임을 확인할 수 있음 -
education변수 또한 중요한 것으로 나타남
b) 선택된 변수들만 적용하기
- 중복 feature 제거 작업을 통해 선택된 feature들을 활용
%%capture --no-display
### 선택된 변수들만 가지고 교차 검증 수행
submission, gbm_fi_selected, valid_scores_selected = model_gbm(train_selected, train_labels,
test_selected, test_ids)
### 결과 저장
model_results = model_results.append(pd.DataFrame({'model': ["GBM", "GBM_SEL"],
'cv_mean': [valid_scores.mean(), valid_scores_selected.mean()],
'cv_std': [valid_scores.std(), valid_scores_selected.std()]}),
sort = True)
### 결과 시각화
model_results.set_index('model', inplace = True)
model_results['cv_mean'].plot.bar(color = 'orange', figsize = (8, 6),
yerr = list(model_results['cv_std']),
edgecolor = 'k', linewidth = 2)
plt.title('Model F1 Score Results')
plt.ylabel('Mean F1 Score (with error bar)')
model_results.reset_index(inplace = True)
10-fold 교차 검증을 적용해보자.
%%capture
### 1. 전체 feature에 대해..
# 5-folds -> 10-folds
submission, gbm_fi, valid_scores = model_gbm(train_set, train_labels, test_set, test_ids,
nfolds = 10, return_preds = False)
submission.to_csv('gbm_10fold.csv', index = False)
%%capture
### 2. 선택된 feature에 대해서만
submission, gbm_fi_selected, valid_scores_selected = model_gbm(train_selected, train_labels,
test_selected, test_ids, nfolds = 10)
submission.to_csv('gmb_10fold_selected.csv', index = False)
### 결과 저장
model_results = model_results.append(pd.DataFrame({'model': ["GBM_10Fold", "GBM_10Fold_SEL"],
'cv_mean': [valid_scores.mean(), valid_scores_selected.mean()],
'cv_std': [valid_scores.std(), valid_scores_selected.std()]}),
sort = True)
### 결과 시각화
model_results.set_index('model', inplace = True)
model_results['cv_mean'].plot.bar(color = 'orange', figsize = (8, 6),
edgecolor = 'k', linewidth = 2,
yerr = list(model_results['cv_std']))
plt.title('Model F1 Score Results')
plt.ylabel('Mean F1 Score (with error bar)')
model_results.reset_index(inplace = True)
-
가장 좋은 모델은
선택된 feature들로10-fold교차 검증을 수행한 모델임 -
최적화를 통해 성능을 더 개선시킬 수 있을 것이라 기대됨
print(f"There are {gbm_fi_selected[gbm_fi_selected['importance'] == 0].shape[0]} features with no importance.")
- 우리가 사용하는 모든 feature들은 Gradient Boosting Machine에서 어느 정도 중요한 것을 확인할 수 있다.
6. 모델 최적화(Model Optimization)
-
교차 검증을 통해
하이퍼 파라미터를 조정하여 머신 러닝 모델에서 최고의 성능을 이끌어 내는 프로세스 -
모델 최적화 Options
1. 수동(Manual)
2. GridSearch
3. RandomSearch
4. 자동화 기법
- 4의 경우
Tree Parzen Estimator와 함께Bayesian Optimization의 수정 버전을 사용하는Hyperopt를 포함한 다수의 라이브러리에서 쉽게 구현 가능 -> 이를 활용
6-1. Hyperopt을 통한 모델 튜닝
베이지안 최적화에는 4가지 부분으로 구성됨
1. 목적 함수: 최대화(또는 최소화)하고 싶은 것
2. 도메인 영역: 검색할 영역
3. 다음 하이퍼 파라미터 선택을 위한 알고리즘: 과거 결과를 사용하여 다음 값을 제안
4. 결과 저장
from hyperopt import hp, tpe, Trials, fmin, STATUS_OK
from hyperopt.pyll.stochastic import sample
import csv
import ast
from timeit import default_timer as timer
a) 목적 함수(Objective Function)
-
모델 하이퍼 파라미터가 사용되고 관련 validation 점수가 반환됨
-
Hyperopt은 최소화 할 점수를 요구함
1 - Macro F1 score를 리턴
-
hyper parameter에 대한 여러 세부 사항들을 설정하는 단계
def objective(hyperparameters, nfolds=5):
global ITERATION
ITERATION += 1
# 하위 샘플
subsample = hyperparameters['boosting_type'].get('subsample', 1.0)
subsample_freq = hyperparameters['boosting_type'].get('subsample_freq', 0)
boosting_type = hyperparameters['boosting_type']['boosting_type']
if boosting_type == 'dart':
hyperparameters['drop_rate'] = hyperparameters['boosting_type']['drop_rate']
# Subsample and subsample frequency to top level keys
hyperparameters['subsample'] = subsample
hyperparameters['subsample_freq'] = subsample_freq
hyperparameters['boosting_type'] = boosting_type
# Whether or not to use limit maximum depth
if not hyperparameters['limit_max_depth']:
hyperparameters['max_depth'] = -1
# Make sure parameters that need to be integers are integers
for parameter_name in ['max_depth', 'num_leaves', 'subsample_for_bin',
'min_child_samples', 'subsample_freq']:
hyperparameters[parameter_name] = int(hyperparameters[parameter_name])
if 'n_estimators' in hyperparameters:
del hyperparameters['n_estimators']
# Using stratified kfold cross validation
strkfold = StratifiedKFold(n_splits = nfolds, shuffle = True)
# Convert to arrays for indexing
features = np.array(train_selected)
labels = np.array(train_labels).reshape((-1 ))
valid_scores = []
best_estimators = []
run_times = []
model = lgb.LGBMClassifier(**hyperparameters, class_weight = 'balanced',
n_jobs=-1, metric = 'None',
n_estimators=10000)
# Iterate through the folds
for i, (train_indices, valid_indices) in enumerate(strkfold.split(features, labels)):
# Training and validation data
X_train = features[train_indices]
X_valid = features[valid_indices]
y_train = labels[train_indices]
y_valid = labels[valid_indices]
start = timer()
# Train with early stopping
model.fit(X_train, y_train, early_stopping_rounds = 100,
eval_metric = macro_f1_score,
eval_set = [(X_train, y_train), (X_valid, y_valid)],
eval_names = ['train', 'valid'],
verbose = 400)
end = timer()
# Record the validation fold score
valid_scores.append(model.best_score_['valid']['macro_f1'])
best_estimators.append(model.best_iteration_)
run_times.append(end - start)
score = np.mean(valid_scores)
score_std = np.std(valid_scores)
loss = 1 - score
run_time = np.mean(run_times)
run_time_std = np.std(run_times)
estimators = int(np.mean(best_estimators))
hyperparameters['n_estimators'] = estimators
# Write to the csv file ('a' means append)
of_connection = open(OUT_FILE, 'a')
writer = csv.writer(of_connection)
writer.writerow([loss, hyperparameters, ITERATION, run_time, score, score_std])
of_connection.close()
# Display progress
if ITERATION % PROGRESS == 0:
display(f'Iteration: {ITERATION}, Current Score: {round(score, 4)}.')
return {'loss': loss, 'hyperparameters': hyperparameters, 'iteration': ITERATION,
'time': run_time, 'time_std': run_time_std, 'status': STATUS_OK,
'score': score, 'score_std': score_std}
b) 도메인 영역(Search Space)
-
domain: 검색할 전체 값의 범위 -
boosting_type이goss인 경우 subsample 비율을 반드시 1.0으로 설정해야 함
space = {
'boosting_type': hp.choice('boosting_type',
[{'boosting_type': 'gbdt',
'subsample': hp.uniform('gdbt_subsample', 0.5, 1),
'subsample_freq': hp.quniform('gbdt_subsample_freq', 1, 10, 1)},
{'boosting_type': 'dart',
'subsample': hp.uniform('dart_subsample', 0.5, 1),
'subsample_freq': hp.quniform('dart_subsample_freq', 1, 10, 1),
'drop_rate': hp.uniform('dart_drop_rate', 0.1, 0.5)},
{'boosting_type': 'goss',
'subsample': 1.0,
'subsample_freq': 0}]),
'limit_max_depth': hp.choice('limit_max_depth', [True, False]),
'max_depth': hp.quniform('max_depth', 1, 40, 1),
'num_leaves': hp.quniform('num_leaves', 3, 50, 1),
'learning_rate': hp.loguniform('learning_rate',
np.log(0.025),
np.log(0.25)),
'subsample_for_bin': hp.quniform('subsample_for_bin', 2000, 100000, 2000),
'min_child_samples': hp.quniform('min_child_samples', 5, 80, 5),
'reg_alpha': hp.uniform('reg_alpha', 0.0, 1.0),
'reg_lambda': hp.uniform('reg_lambda', 0.0, 1.0),
'colsample_bytree': hp.uniform('colsample_by_tree', 0.5, 1.0)
}
sample(space)
c) 알고리즘
-
다음 값을 선택하는 알고리즘은
Tree Parzen Estimator로,Bayes rule을 사용하여 목적 함수의 대체 모델을 구성함 -
objective function을 최대화 하는 대신 대체 모델의
Expected Improvement (EI)를 최대화
algo = tpe.suggest
d) 결과 저장
- 결과를 저장하기 위해 두 가지 방법을 활용
1. Trials object: 목적 함수에서 반환된 모든 것을 저장
2. 반복할 때마다 CSV 파일에 쓰기
# 결과 저장하기
trials = Trials()
# 파일 열기, 연결하기
OUT_FILE = 'optimization.csv'
of_connection = open(OUT_FILE, 'w')
writer = csv.writer(of_connection)
MAX_EVALS = 100
PROGRESS = 10
N_FOLDS = 5
ITERATION = 0
# 컬럼명 작성
headers = ['loss', 'hyperparameters', 'iteration', 'runtime', 'score', 'std']
writer.writerow(headers)
of_connection.close()
%%capture --no-display
display("Running Optimization for {} Trials.".format(MAX_EVALS))
# 최적화 수행
best = fmin(fn = objective, space = space, algo = tpe.suggest, trials = trials,
max_evals = MAX_EVALS)
-
학습을 재개하기 위해서 동일한
trials객체를 전달하고 최대 반복 횟수를 늘리면 됨 -
나중에 활용하기 위해 trials를
json으로 저장할 수 있음
import json
# trial 결과 저장
with open('trials.json', 'w') as f:
f.write(json.dumps(str(trials)))
6-2. 최적화된 모델 사용하기
### 최적화 된 모델 결과 가져오기
results = pd.read_csv(OUT_FILE).sort_values('loss', ascending = True).reset_index()
results.head()
### 결과 시각화
plt.figure(figsize = (8, 6))
sns.regplot('iteration', 'score', data = results)
plt.title("Optimization Scores")
plt.xticks(list(range(1, results['iteration'].max() + 1, 3)))
### 최적 parameter 선택
best_hyp = ast.literal_eval(results.loc[0, 'hyperparameters'])
best_hyp
%%capture
### 선택된 feature들로만 모델링
submission, gbm_fi, valid_scores = model_gbm(train_selected, train_labels,
test_selected, test_ids,
nfolds = 10, return_preds=False)
model_results = model_results.append(pd.DataFrame({'model': ["GBM_OPT_10Fold_SEL"],
'cv_mean': [valid_scores.mean()],
'cv_std': [valid_scores.std()]}),
sort = True).sort_values('cv_mean', ascending = False)
%%capture
### 전체 feature로 모델링
submission, gbm_fi, valid_scores = model_gbm(train_set, train_labels,
test_set, test_ids,
nfolds = 10, return_preds=False)
model_results = model_results.append(pd.DataFrame({'model': ["GBM_OPT_10Fold"],
'cv_mean': [valid_scores.mean()],
'cv_std': [valid_scores.std()]}),
sort = True).sort_values('cv_mean', ascending = False)
model_results.head()
### 제일 성능이 좋은 모델로 예측 후 결과 저장
submission.to_csv('gbm_opt_10fold_selected.csv', index = False)
-
이 시점에서 성능을 개선하기 위해 최적화를 계속하거나, 더 많은 기능 엔지니어링/ 추가적인 모델 스택 또는 앙상블을 시도하거나, 차원 축소 또는 오버샘플링과 같은 더 실험적인 방법을 검토할 수 있음
- 예측값을 검토하여 모델이 어디서 오류를 범하고 있는지를 확인할 예정
_ = plot_feature_importances(gbm_fi)
7. 예측 확인
-
test 데이터에서 예측된 label의 분포를 시각화하여 확인할 수 있음
-
train 데이터와 동일한 분포를 보일 것으로 예상됨
-
가구별 예측에 관심이 있기에, 각 가구에 대한 예측만 확인하여 train 데이터의 예측과 비교
-
-
다음 히스토그램은 절대 카운트 대신 상대적인 빈도를 표시하는 정규화 된 값
- 원본의 데이터 수와 validation 데이터에서의 데이터 수가 다르기 때문
preds = submission_base.merge(submission, on = 'Id', how = 'left')
preds = pd.DataFrame(preds.groupby('idhogar')['Target'].mean())
# train data에서의 label의 분포 시각화
fig, axes = plt.subplots(1, 2, sharey = True, figsize = (12, 6))
heads['Target'].sort_index().plot.hist(normed = True,
edgecolor = r'k',
linewidth = 2,
ax = axes[0])
axes[0].set_xticks([1, 2, 3, 4])
axes[0].set_xticklabels(poverty_mapping.values(), rotation = 60)
axes[0].set_title('Train Label Distribution')
# Plot the predicted labels
preds['Target'].sort_index().plot.hist(normed = True,
edgecolor = 'k',
linewidth = 2,
ax = axes[1])
axes[1].set_xticks([1, 2, 3, 4])
axes[1].set_xticklabels(poverty_mapping.values(), rotation = 60)
plt.subplots_adjust()
plt.title('Predicted Label Distribution')
heads['Target'].value_counts()
preds['Target'].value_counts()
-
약간의 차이가 있지만 train label의 분포에 가까움
target = 4가 아닌target = 3이 과도하게 표현됨
-
불균형 분류 문제를 해결하기 위해 소수의 클래스를 oversampling하는 방법이 있음
imbalanced learn라이브러리를 활용하여 쉽게 구현 가능
7-1. 검증(Validation)
-
test용 예측을 통해 label의 분포를 train 데이터에서의 분포와 비교할 수 있음
-
예측을 실제 값과 비교하기 위해서는 train 데이터를 별도의 validation 세트로 분할해야 함
-
1000개의 데이터를 검증에 활용
-
이후
confusion matrix를 통해 오분류 탐지
-
from sklearn.model_selection import train_test_split
# 데이터 분할
X_train, X_valid, y_train, y_valid = train_test_split(train_selected,
train_labels,
test_size = 1000,
random_state = 10)
# 모델 생성/학습
model = lgb.LGBMClassifier(**best_hyp,
class_weight = 'balanced',
random_state = 10)
model.fit(X_train, y_train);
# 검증 수행
valid_preds = model.predict_proba(X_valid)
preds_df = pd.DataFrame(valid_preds, columns = [1, 2, 3, 4])
# 예측값으로 변환
preds_df['prediction'] = preds_df[[1, 2, 3, 4]].idxmax(axis = 1)
preds_df['confidence'] = preds_df[[1, 2, 3, 4]].max(axis = 1)
preds_df.head()
print('F1 score:', round(f1_score(y_valid, preds_df['prediction'], average = 'macro'), 5))
📌 오차 행렬(confusion matrix)
- 예측과 실제 값의 차이를 보여줌으로써 모형이 혼동하는 지점을 파악할 수 있음
from sklearn.metrics import confusion_matrix
import itertools
### 오차 행렬을 생성하는 함수
def plot_confusion_matrix(cm, classes,
normalize = False,
title = 'Confusion matrix',
cmap = plt.cm.Oranges):
### 정규화
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
print(cm)
plt.figure(figsize = (10, 10))
plt.imshow(cm, interpolation='nearest', cmap = cmap)
plt.title(title, size = 24)
plt.colorbar(aspect = 4)
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation = 45, size = 14)
plt.yticks(tick_marks, classes, size = 14)
fmt = '.2f' if normalize else 'd' # formatting
thresh = cm.max() / 2. # 임계값 설정
### Labeling
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt), fontsize = 20,
horizontalalignment = "center",
color = "white" if cm[i, j] > thresh else "black")
plt.grid(None)
plt.tight_layout()
plt.ylabel('True label', size = 18)
plt.xlabel('Predicted label', size = 18)
cm = confusion_matrix(y_valid, preds_df['prediction']) # 오차 행렬
plot_confusion_matrix(cm, classes = ['Extreme', 'Moderate', 'Vulnerable', 'Non-Vulnerable'],
title = 'Poverty Confusion Matrix')
-
Confusion Matrix 해석-
대각선:(예측 값) == (실제 값)
-
나머지: 잘못된 값
-
-
현재 모델은
poverty = extreme인 25개의 관측치를 정확하게 예측한 반면, 나머지 26개의 관측치의 경우poverty = moderate라고 잘못 예측함 -
전반적으로 모델은
poverty = non-vulnerable인 가구를 식별하는 데만 매우 정확하다는 것을 확인할 수 있음 -
실제 레이블에 대한 오차 행렬을 정규화하여 각 클래스에서 예측된 실제 레이블의 백분율을 확인할 수 있음
plot_confusion_matrix(cm, normalize = True,
classes = ['Extreme', 'Moderate', 'Vulnerable', 'Non-Vulnerable'],
title = 'Poverty Confusion Matrix')
-
poverty = non-vulnerable외의 클래스는 잘 구분하지 못하고 있는 것을 확인할 수 있음 -
poverty = vulnerable중 약 35%만 정확하게 식별하고, 더 많은 수는 잘못 분류하고 있음
불균형 데이터 분류 문제는 모델이 정확히 예측을 하는 데 어려움이 있음
- 이러한 경우 oversampling이나 여러 영역에서 다양한 모델을 학습하는 등의 방법을 택할 수는 있지만,
데이터를 최대한 많이 모으는 것이 권장됨
7-2. 차원 축소(Dimension Reduction)
-
선택된 데이터 세트에 몇 가지 다른 차원 축소 방법을 적용할 수 있음
- 시각화 또는 기계 학습을 위한 전처리 방법으로 사용할 수 있음
-
종류
-
PCA(Principal Components Analysis): 데이터에서 가장 큰 변동이 일어나는 차원을 찾음 -
ICA(Independent Components Analysis): 다변량 신호를 독립적인 신호로 분리하려고 시도 -
TSNE(T-distributed Stochastic Neighbor Embedding): 고차원 데이터를 저차원 매니폴드에 매핑하여 데이터 내의 로컬 구조를 유지 -
UMAP(Uniform Manifold Approximation and Projection): 데이터를 저차원 매니폴드에 매핑하지만 TSNE보다 더 많은 전역 구조를 보존하려고 하는 비교적 새로운 기술
-
네 가지 방법 모두 파이썬에서 구현하기가 비교적 간단함
-
시각화를 위해 선택한 형상을 3차원으로 매핑한 다음 모델링 형상으로
PCA,ICA및UMAP을 사용TSNE에는 변환 방법이 없으므로 전처리에 사용할 수 없음
!pip install umap
from umap import UMAP
from sklearn.decomposition import PCA, FastICA
from sklearn.manifold import TSNE
n_components = 3 # 3차원
### 차원 축소를 위한 객체 생성
umap = UMAP(n_components = n_components)
pca = PCA(n_components = n_components)
ica = FastICA(n_components = n_components)
tsne = TSNE(n_components = n_components)
train_df = train_selected.copy()
test_df = test_selected.copy()
for method, name in zip([umap, pca, ica, tsne],
['umap', 'pca', 'ica', 'tsne']):
# TSNE는 변환 method가 없음
if name == 'tsne':
start = timer()
reduction = method.fit_transform(train_selected)
end = timer()
else:
start = timer()
reduction = method.fit_transform(train_selected)
end = timer()
test_reduction = method.transform(test_selected)
# Add components to test data
test_df['%s_c1' % name] = test_reduction[:, 0]
test_df['%s_c2' % name] = test_reduction[:, 1]
test_df['%s_c3' % name] = test_reduction[:, 2]
# Add components to training data for visualization and modeling
train_df['%s_c1' % name] = reduction[:, 0]
train_df['%s_c2' % name] = reduction[:, 1]
train_df['%s_c3' % name] = reduction[:, 2]
# 소요 시간 출력
print(f'Method: {name} {round(end - start, 2)} seconds elapsed.')
from mpl_toolkits.mplot3d import Axes3D
def discrete_cmap(N, base_cmap=None):
"""Create an N-bin discrete colormap from the specified input map
Source: https://gist.github.com/jakevdp/91077b0cae40f8f8244a"""
base = plt.cm.get_cmap(base_cmap)
color_list = base(np.linspace(0, 1, N))
cmap_name = base.name + str(N)
return base.from_list(cmap_name, color_list, N)
cmap = discrete_cmap(4, base_cmap = plt.cm.RdYlBu)
train_df['label'] = train_labels
### 각각의 방법을 활용하여 시각화
for method, name in zip([umap, pca, ica, tsne],
['umap', 'pca', 'ica', 'tsne']):
fig = plt.figure(figsize = (8, 8))
ax = fig.add_subplot(111, projection='3d')
p = ax.scatter(train_df['%s_c1' % name], train_df['%s_c2' % name], train_df['%s_c3' % name],
c = train_df['label'].astype(int), cmap = cmap)
plt.title(f'{name.capitalize()}', size = 22)
fig.colorbar(p, aspect = 4, ticks = [1, 2, 3, 4])
-
이러한 그래프에서 많은 군집화를 보기는 어려움
- 사용 가능한 데이터를 고려할 때 빈곤 수준을 분리하는 것이 어려움을 의미
-
마지막으로
PCA,ICA및UMAP을 활용하여 추가적으로 feature의 개수를 줄여 모델을 학습시킬 수 있음
train_df, test_df = train_df.align(test_df, axis = 1, join = 'inner')
%%capture
submission, gbm_fi, valid_scores = model_gbm(train_df, train_labels,
test_df, test_ids, nfolds = 10,
hyp = best_hyp)
submission.to_csv('gbm_opt_10fold_dr.csv', index = False)
model_results = model_results.append(pd.DataFrame({'model': ["GBM_OPT_10Fold_DR"],
'cv_mean': [valid_scores.mean()],
'cv_std': [valid_scores.std()]}),
sort = True)
model_results = model_results.sort_values('cv_mean')
model_results.set_index('model', inplace = True)
model_results['cv_mean'].plot.bar(color = 'orange', figsize = (10, 8),
edgecolor = 'k', linewidth = 2,
yerr = list(model_results['cv_std']))
plt.title('Model F1 Score Results')
plt.ylabel('Mean F1 Score (with error bar)')
model_results.reset_index(inplace = True)
-
차원이 감소된 성분은 모형의 전체 성능에 약간 영향을 미침
- train data의 과적합을 초래할 수 있음
_ = plot_feature_importances(gbm_fi)
-
차원 축소된 feature의 feature importance가 매우 높음
- overfitting이 발생할 수 있음
-
차원 축소는 label 정보를 사용하지 x
- 모형의 예측에 중요한 정보들을 포함하지 못할 수도 있음
7-3. 단일 트리 모델 시각화
-
RandomForestClassifier에서 하나의 의사 결정 트리를 살펴볼 수 있음
- 가시성을 위해
max_depth를 제한한 다음 트리를 전체적으로 확장함
- 가시성을 위해
model = RandomForestClassifier(max_depth = 3, n_estimators=10)
model.fit(train_selected, train_labels)
### 하나의 트리를 추출
estimator_limited = model.estimators_[5]
estimator_limited
- 훈련된 트리를 가져와
export_graphviz를 사용하여.dot파일로 내보냄
### 단일 트리 모형 내보내기
from sklearn.tree import export_graphviz
export_graphviz(estimator_limited, out_file='tree_limited.dot', feature_names = train_selected.columns,
class_names = ['extreme', 'moderate' , 'vulnerable', 'non-vulnerable'],
rounded = True, proportion = False, precision = 2, filled = True)
.dot파일을.png파일로 변환
!dot -Tpng tree_limited.dot -o tree_limited.png
IPython.display을 활용하여 Jupyter Notebook에서 트리를 확인
### 트리 시각화
from IPython.display import Image
Image(filename = 'tree_limited.png')
📌 최대 깊이 제한 없이 트리 시각화
-
깊이 제한이 없으면, 트리는 무한정 성장할 수 있음
- 따라서, 일반적으로는 약간의 제한을 두는 것이 도움됨
# 깊이 제한 x
model = RandomForestClassifier(max_depth = None, n_estimators=10)
model.fit(train_selected, train_labels)
estimator_nonlimited = model.estimators_[5]
export_graphviz(estimator_nonlimited, out_file='tree_nonlimited.dot', feature_names = train_selected.columns,
class_names = ['extreme', 'moderate' , 'vulnerable', 'non-vulnerable'],
rounded = True, proportion = False, precision = 2)
!dot -Tpng tree_nonlimited.dot -o tree_nonlimited.png -Gdpi=600
Image(filename = 'tree_nonlimited.png')
~도저히 알아볼 수 없음~
8. 결론
-
실제 문제에 대한 전체 데이터 과학 솔루션의 단계별 구현을 수행
-
프로세스 정리>
1. 문제 이해
2. 탐색적 데이터 분석(EDA)
- 데이터 문제 처리
- 결측값 입력
3. 특성 공학(Feature Engineering)
- 데이터 집계(aggregation)
- 단계별 피쳐 선택
4. 모델 선택
- 다양한 모델을 시도하여 어떤 모델이 가장 유력한지 확인
- 기능 선택 기능도 작동 가능
5. 모델 최적화
- 최고 성능 모델을 선택하고 튜닝
6. 모델 최적화
7. 예측 검토
- 모델의 단점을 식별합니다
8. 새로운 기술을 시도
-
서론에서 언급한 바와 같이, 이러한 단계는 일반적인 순서를 가지고 있지만, 성능에 만족되지 못하는 경우 모델링 후 피쳐 엔지니어링/선택 항목으로 되돌아가는 경우도 많음
- 예측을 조사한 후 모델링 단계로 돌아가서 접근 방식을 다시 생각할 수도 있음
-
기계 학습은 대부분 경험적이라는 것을 명심해야 함
- 확립된 모범 사례가 거의 없으므로 가장 효과적인 방법을 결정하기 위해 지속적으로 경험해야 함
-
우리의 최종 모델은 다른 경쟁 모델들에 비해 우수하지만, 전체적으로 매우 정확하지는 않음
-
성능을 개선할 수 있는 방법이 있을 수 있지만, 전반적으로
데이터가 부족하여 예외적인 메트릭을 달성할 수 없음 -
결국 데이터 과학 프로젝트의 성패는
사용 가능한 데이터의 품질과 양에 달려 있음
-
📌 추가적으로 할 수 있는 것들
- 추가적인 hyper parameter tuning
- 모델을 최적화하는 데 많은 시간을 투자하지 않았으며, 최적화를 위해 시도할 수 있는 다른 패키지가 있음
- 추가적인 feature selection
- 동일한 성능을 얻기 위해 모든 feature을 유지할 필요는 없음
-
소수의 class에 대한 oversampling, 많은 class에 대한 undersampling
-
여러 모델을 앙상블/스태킹
- 데이터의 다른 부분에 대해 모델을 훈련시키고 그들의 예측을 결합하여 클래스를 더 잘 분리할 수 있음